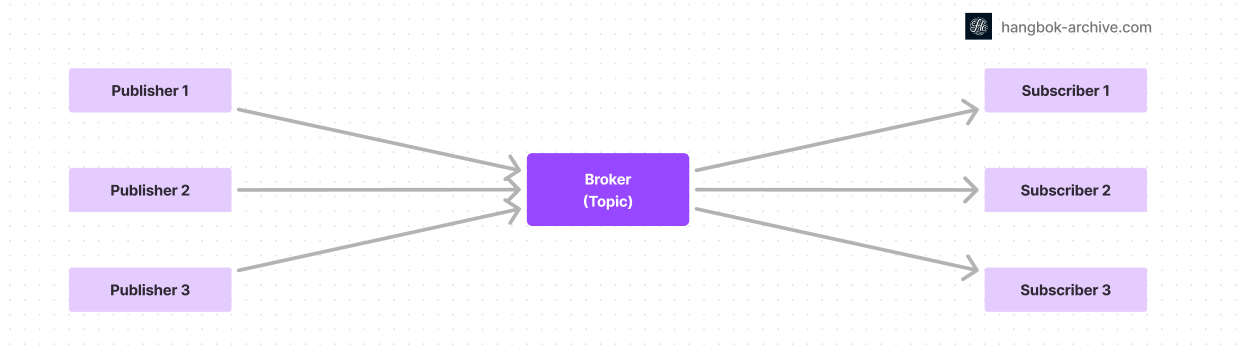
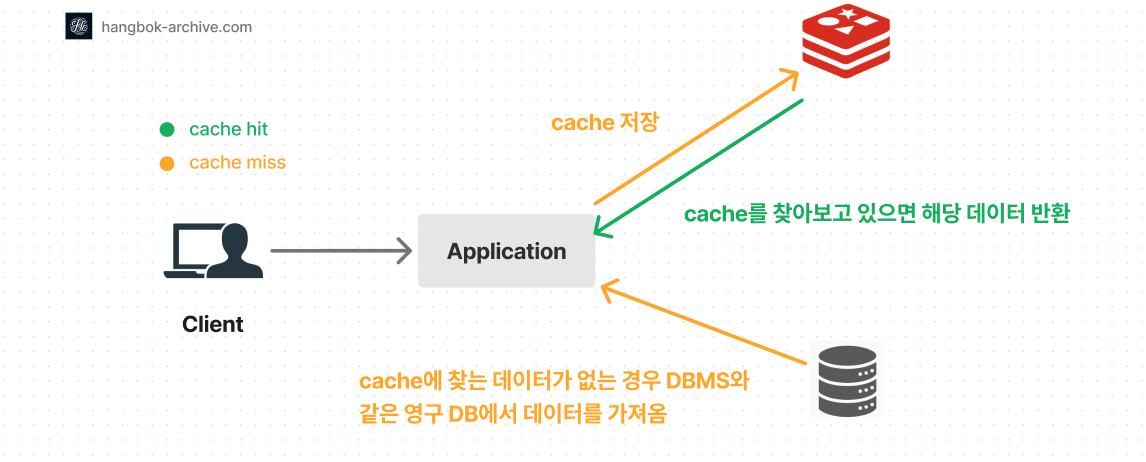
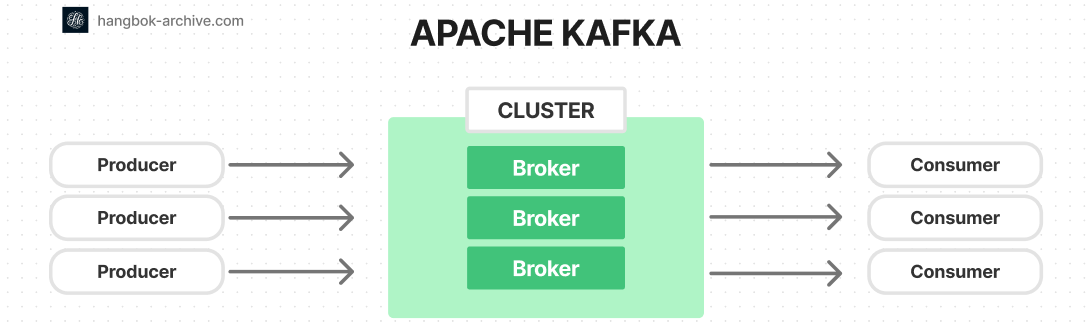
LangGraph Durable Execution
개념 LangGraph 진행 상황을 저장해서 중단된 지점부터 정확히 재개할 수 있는 실행 방식입니다. Human-in-the-loop, 장기 실행 작업, 오류 복구에 유용합니다. 견고한 실행을 구성하는 법 1. Checkpointer 지정 다양한 저장형태의 checkpointer를 이용 가능. 운영 서비스가 아닌 경우 InMemorySaver로 시작해도 무방 2. Thread ID 지정 3. Side Effect(e.g., file writes, API calls)는 Task로 래핑 결정성과 일관된 재실행 … Read more