본 포스트에서는 AI 하네스의 개념적 정의를 명확히 하고, 왜 ‘하네스가 곧 성능’이라는 주장이 설득력을 얻는지에 대한 기술적 근거들에 대해 정리하였습니다.
인공지능 연구의 패러다임이 모델의 가중치(Weights)와 아키텍처 중심에서 시스템 전체를 감싸는 ‘하네스(Harness)’ 아키텍처 중심으로 급격하게 이동하고 있습니다
과거에는 대규모 언어 모델(LLM)의 성능을 결정짓는 핵심이 단순히 파라미터 수나 학습 데이터의 양에 있다고 믿었으나, 최근의 연구와 실무적 사례들은 동일한 모델이라 할지라도 이를 둘러싼 하네스의 설계에 따라 성능 지표가 극적으로 변화할 수 있음을 입증하고 있습니다.[1, 2]
하네스는 단순한 소프트웨어 래퍼(Wrapper)를 넘어, 모델의 문맥 수명 주기를 관리하고 외부 도구와의 인터페이스를 규정하며 추론의 일관성을 보장하는 핵심 인프라로 정의됩니다.[1]
추가로 모델의 가중치를 수정하지 않고도 하네스의 변경만으로 성능을 개선하는 것이 어떻게 가능한지, 그 이면에 숨겨진 프롬프트 민감도, 구조적 생성(Structured Generation), 그리고 에이전틱(Agentic) 피드백 루프의 기제를 분석하였습니다.[2, 3, 4]
AI 하네스란?
Anthropic 등 주요 AI 기업 최근 LLM이 단순 텍스트 생성을 넘어 외부 도구를 사용하고 장기적인 다단계 작업을 수행하는 에이전트로 진화하면서 ‘에이전트 하네스’라는 개념이 새롭게 등장했습니다.
이 개념은 한 명의 창시자가 발명했다기보다는, 단발성(One-shot) 상호작용의 한계를 극복하고 장기 기억 및 도구 제어 능력을 부여하기 위해 업계 전반에서 자연스럽게 대두된 아키텍처입니다.
특히 Anthropic은 자사의 Claude Agent SDK를 “범용 에이전트 하네스“라고 지칭하며, 긴 수명 주기를 갖는 에이전트의 문맥과 로그를 관리하는 시스템으로 이 용어를 적극 활용하고 있습니다.
LangChain 역시 자사 프레임워크 위에 구축된 AI 시스템인 ‘DeepAgents’를 에이전트 하네스로 소개하고 있습니다.
사실상 LLM 모델 그 자체를 제외한 주변의 모든 필수 소프트웨어 인프라로 규정했습니다.
AI 하네스 구성 요소
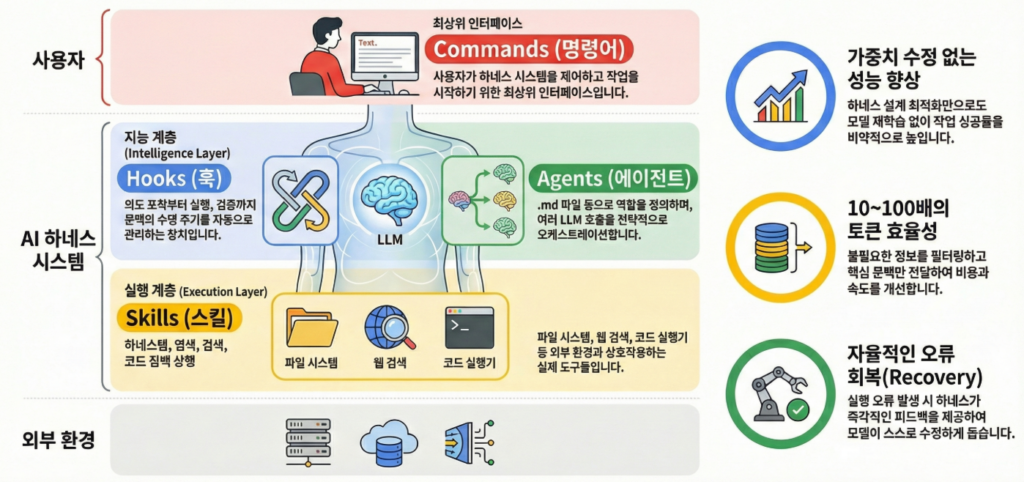
Hooks
정의: 에이전트 세션의 특정 라이프사이클 이벤트(시작, 종료 등)가 발생할 때 자동으로 실행되는 스크립트나 명령어
실전 활용 예시:
- 에이전트가 코드를 무작정 탐색하며 토큰을 낭비하는 것을 방지
- 시스템 시작 시
grep def같은 명령을 시작 훅(startup hook)으로 실행 - 코드베이스의 전체 함수 구조를 모델에게 미리 제공하여 효율적인 탐색 유도
핵심 가치: 반복적인 초기 작업을 자동화하여 토큰 효율성 극대화
Agents
정의: 하네스 환경에서 동작하는 AI 개체로, 마크다운(.md) 파일 형태로 선언적으로 정의
파일 구성 요소:
| 항목 | 설명 |
|---|---|
| Persona | 에이전트가 수행할 character와 전문성 정의 |
| 핵심 프롬프트 | 시스템 프롬프트 및 행동 지침 |
| 스킬 목록 | 에이전트가 사용 가능한 도구들의 명시적 선언 |
장점: 코딩 없이 텍스트 파일만 수정하여 에이전트의 행동과 능력을 쉽게 커스터마이징 가능
Skills
정의: 모델이 텍스트 생성을 넘어 외부 환경과 실제 상호작용하기 위한 도구 및 플러그인
주요 예시:
- 로컬 파일 시스템 읽기/쓰기
- 웹 검색
- 코드 실행 (Python, Bash 등)
- 데이터베이스 쿼리
- API 호출
핵심 역할: 모델의 “행동 수단”을 확장하여 실제 세계와의 인터페이스 담당
Commands
정의: 사용자가 터미널(CLI) 환경에서 하네스 프로그램 자체를 제어하기 위한 명령 체계
AI 지시 vs 하네스 제어의 차이:
- AI에게 지시: “이 코드를 리팩토링해줘” → 모델의 입력으로 처리
- 하네스 명령:
/cost,/reset,/save등 → 하네스 시스템 직접 제어
대표적 예시:
| 명령어 | 기능 |
|---|---|
/cost | 현재 세션에서 소비된 토큰 비용을 달러 단위로 표시 |
/compact | 대화 문맥 압축 및 요약 |
/clear | 세션 초기화 |
핵심 가치: 사용자가 AI 대화와 별개로 시스템 상태를 모니터링하고 관리할 수 있는 제어 수단 제공
Claude Agent Harness와 LangChain 비교
사실 Claude의 하네스라는 것은 LangChain의 deep agent와 유사합니다.
AI 서비스 개발자라면 claude harness가 생각보다 별거 아니라는 것을 알 수 있습니다
Claude가 조금 더 완성된 도구들을 조립해서 사용하는 느낌입니다.

LangChain 개발진 역시 이러한 흐름에 맞춰 최근 LangChain 및 LangGraph 위에서 기본 프롬프트, 도구 처리, 파일 시스템 접근 기능 등을 ‘기본 탑재(Batteries included)’하여 바로 사용할 수 있게 만든 DeepAgents라는 범용 에이전트 하네스를 새롭게 선보이기도 했습니다.
즉, 개발자가 처음부터 코드를 짜서 엮어야 하는 LangChain의 복잡성을 줄이고, 훅과 마크다운 설정만으로 즉시 사용할 수 있게 추상화한 결과물이 바로 최신 에이전트 하네스 기술입니다.
AI Agent harness의 주 용도
agent harness는 범용적으로 탄생했지만, 실상은 주로 바이브 코딩 용도로 주로 사용되고 있습니다.
현재 ‘하네스’를 직접 다루고 구축하는 1차적인 사용자는 소프트웨어 개발자와 AI 시스템 아키텍트입니다
단순한 챗봇과 달리, 하네스는 다음과 같이 외부 환경과 상호작용하며 복잡하고 장기적인(long-running) 작업을 수행하는 상황에서 주로 쓰입니다.
소프트웨어 엔지니어링: 여러 세션에 걸쳐 복잡한 소프트웨어 프로젝트의 코드를 작성, 실행, 디버깅, 테스트하는 코딩 에이전트 환경.
시스템 제어 및 분석: 클라우드 인프라(SRE)를 관리하거나, 코드의 보안 취약점을 검사하고 수정하는 작업, 데이터베이스 및 웹 API를 직접 쿼리하고 대규모 문서를 분석하는 작업.
AI 서비스 런타임 구축: LangChain의 DeepAgents처럼 개발자가 새로운 AI 서비스를 만들 때, 처음부터 메모리나 도구 연결을 짜지 않고 즉시 사용할 수 있는 ‘완성된 런타임 인프라’로 사용됩니다
AI 하네스만으로 LLM 성능 개선하기
프롬프트 민감도와 형식적 최적화의 영향
모델의 가중치를 단 한 번도 업데이트하지 않고도 하네스의 변경만으로 성능이 개선되는 가장 근본적인 이유는 모델이 입력 형식의 미세한 변화에 극도로 민감하기 때문입니다.[4]
Sclar 등의 연구에 따르면, 의미는 완전히 동일하지만 포맷팅만 다른 프롬프트를 적용했을 때 Llama-2-13B 모델의 경우 성능 차이가 최대 76 accuracy points까지 벌어지는 현상이 관찰되었습니다.[4]
이러한 현상은 모델이 사전 학습 과정에서 접했던 데이터 패턴과의 유사성에 기인합니다.
하네스가 모델의 임베딩 공간에서 더 명확하거나 익숙한 패턴으로 문맥을 구조화할 경우, 모델의 다음 토큰 예측 확률 분포가 더 뾰족해지며 결과적으로 추론의 정확도가 비약적으로 향상됩니다.[8, 9]
이는 프롬프트 디자인 자체가 모델의 가중치만큼이나 중요한 성능 결정 인자임을 시사합니다.[10]
| 프롬프트 변동 요인 | 성능에 미치는 영향 | 데이터 근거 |
|---|---|---|
| 포맷팅(공백, 줄바꿈) | 토큰화 정렬 및 확률 분포 변화 유발 | 최대 76%p 차이 발생 [4] |
| 대소문자 및 구두점 | 모델의 지시 이행 의도 파악 강도 조절 | 무작위 샘플링 시 높은 분산 보고 [11] |
| 답변 후보 순서 | 모델의 특정 레이블 선호 편향 자극 | 순서 변경 시 정확도 유의미한 하락 [12] |
구조적 생성을 통한 출력 통제
성능 개선의 또 다른 강력한 기제는 하네스 수준에서 적용되는 ‘구조적 생성’입니다.
이는 모델이 자유로운 텍스트를 출력하게 두는 대신, 정규 표현식(Regex)이나 JSON 스키마를 강제하여 모델의 출력 공간을 논리적으로 제한하는 방식입니다.[3]
GSM8K 수학 벤치마크 실험에서 구조적 생성을 적용한 결과, 분석된 8개의 모델 모두에서 비구조적 생성 대비 최대 70% 이상의 성능 향상이 보고되었습니다.[3]
구조적 생성이 성능을 높이는 이유는 모델의 ‘사고 제어(Thought-Control)’ 기능 때문입니다.
하네스는 Chain-of-Thought 추론 단계에서 모델이 일정 수준 이상의 사고 과정을 거치도록 글자 수를 제어하거나 형식을 규정함으로써, 모델이 성급하게 결론에 도달하여 범할 수 있는 논리적 오류를 미연에 방지합니다.[3]
Reference
- What is an agent harness in the context of large-language models? | Parallel Web Systems, https://parallel.ai/articles/what-is-an-agent-harness
- Improving 15 LLMs at Coding in One Afternoon. Only the Harness …, https://news.ycombinator.com/item?id=46988596
- Structured Generation Improves LLM performance: GSM8K Benchmark, https://blog.dottxt.ai/performance-gsm8k.html
- Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting – arXiv.org, https://arxiv.org/html/2310.11324v2
- EleutherAI’s lm-evaluation-harness: Architecture and Configuration – Earl Potters, https://slyracoon23.github.io/blog/posts/2025-03-21_eleutherai-evaluation-methods.html
- LLM evaluation | EleutherAI lm-evaluation-harness | by tony Kuo | Disassembly – Medium, https://medium.com/disassembly/llm-evaluation-eleutherai-lm-evaluation-harness-cc379495d545
- Evaluating LLMs — EleutherAI, https://www.eleuther.ai/projects/large-language-model-evaluation
- [PDF] Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting | Semantic Scholar, https://www.semanticscholar.org/paper/Quantifying-Language-Models%27-Sensitivity-to-in-or%3A-Sclar-Choi/17a6116e5bbd8b87082cbb2e795885567300c483
- Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting – athina.ai, https://blog.athina.ai/quantifying-language-models-sensitivity-to-spurious-features-in-prompt-design-or-how-i-learned-to-start-worrying-about-prompt-formatting
- Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting | NSF Public Access Repository, https://par.nsf.gov/biblio/10520219-quantifying-language-models-sensitivity-spurious-features-prompt-design-how-learned-start-worrying-about-prompt-formatting
- Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting | OpenReview, https://openreview.net/forum?id=RIu5lyNXjT
- Changing Answer Order Can Decrease MMLU Accuracy – OpenReview, https://openreview.net/pdf?id=MISIKTzC22
- Over Half My Model’s Correct Answers Were Scored as Wrong – Medium, https://medium.com/@gsagar/over-half-my-models-correct-answers-were-scored-as-wrong-2c3ada1b632f
- Open-LLM performances are plateauing, let’s make the leaderboard steep again – Hugging Face, https://huggingface.co/spaces/open-llm-leaderboard/blog
- The Overfitting Crisis in LLM Workflows: Learning from Machine Learning’s Past Mistakes, https://openreview.net/forum?id=maMnVCHl8J
- Forget What You Know about LLMs Evaluations – LLMs are Like a Chameleon, https://www.researchgate.net/publication/388920744_Forget_What_You_Know_about_LLMs_Evaluations_-_LLMs_are_Like_a_Chameleon
- Forget What You Know about LLMs Evaluations – LLMs are Like a Chameleon – arXiv, https://arxiv.org/html/2502.07445v2
- Forget What You Know about LLMs Evaluations – LLMs are Like a Chameleon – arXiv, https://arxiv.org/html/2502.07445v1
- How Much Do Large Language Model Cheat on Evaluation? Benchmarking Overestimation under the One-Time-Pad-Based Framework – arXiv, https://arxiv.org/html/2507.19219v1
- Daily Papers – Hugging Face, https://huggingface.co/papers?q=testing%20leakage
- Demystifying LLM Leaderboards: What You Need to Know – Shakudo, https://www.shakudo.io/blog/demystifying-llm-leaderboards-what-you-need-to-know
- 2025 LLM Year in Review | karpathy, https://karpathy.bearblog.dev/year-in-review-2025/