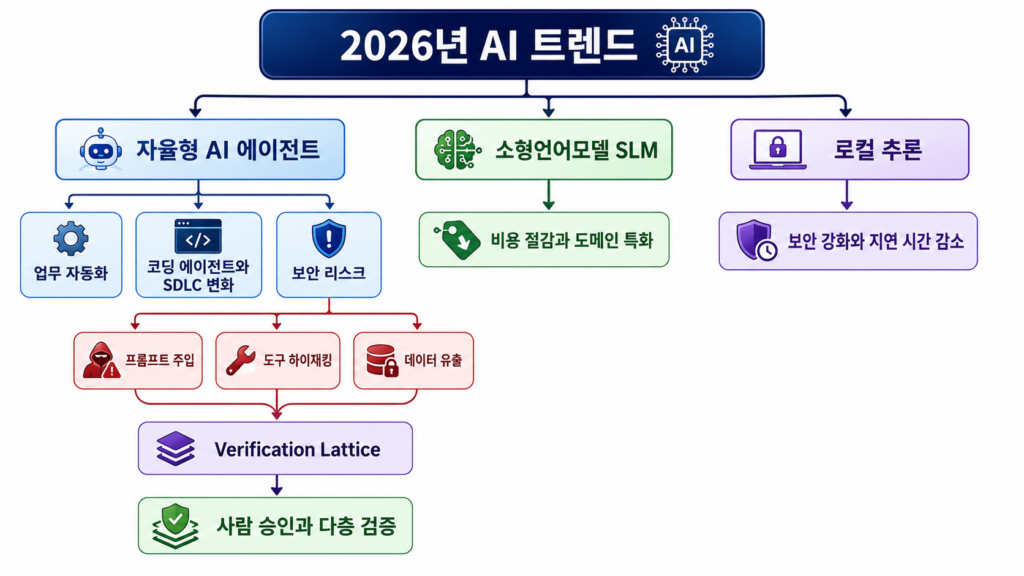
2026년 06월 둘째주 AI 뉴스의 핵심은 자율형 AI 에이전트, 코딩 에이전트, 소형언어모델(SLM), 로컬 추론으로 압축됩니다.
이제 AI 경쟁은 무조건 더 거대한 모델을 만드는 단계에서 벗어나, 더 가볍고 안전하며 스스로 판단하는 AI 시스템을 실제 업무와 개발 환경에 어떻게 연결할 것인가로 이동하고 있습니다.
이번 글에서는 자율형 AI 에이전트가 업무 자동화와 소프트웨어 개발 방식을 어떻게 바꾸는지, SLM과 로컬 추론이 비용·보안·지연 시간 문제를 어떻게 해결하는지, 그리고 기업이 AI 도입 과정에서 반드시 고려해야 할 에이전트 보안 리스크와 검증 구조를 함께 정리합니다.
자율형 에이전트와 코딩 혁명
에이전트의 시대: 단순 비서에서 ‘디지털 동료’로의 도약
인공지능은 단순히 질문에 답하는 챗봇 단계를 지나, 명확한 목표만 주어지면 스스로 판단하여 최선의 도구를 선택하고 결과를 도출하는 ‘자율형 AI 에이전트’로 진화했습니다.[1]
시장 조사 지표에 따르면 2026년 말까지 엔터프라이즈 애플리케이션의 80% 이상이 에이전트 아키텍처를 내재화하고, 전 세계 주요 업무 역할의 약 40%가 이러한 자율 에이전트와의 협업 체계로 재편될 전망입니다.[1]
특히 최근 OpenAI가 전격 공개한 GPT-5.5는 에이전트 수행력 측면에서 기존의 강력한 대안이었던 Claude Mythos를 앞지르며 기술적 도약의 정점을 보여주었습니다.[2]
단일 업무를 넘어 법률, 재무, 인사 부서의 에이전트들이 서로 정보를 주고받으며 신규 임직원 온보딩 프로세스를 자동화하는 ‘다중 에이전트(Multi-agent) 시스템’ 역시 실질적인 프로덕션 수준에서 원활하게 가동되고 있습니다.[1]\
코드 한 줄 없이 앱을 완성하는 소프트웨어 개발 수명 주기(SDLC)의 해체
개발 현장에서 느껴지는 변화의 파고는 한층 더 파격적입니다.[1, 3]
기존에 개발자 3명이 달라붙어 기획, 구현, 테스트, 배포까지 최소 6주일이 소요되던 고부하 시스템 구축 태스크가, 2026년 현재는 1명의 오케스트레이터와 고도화된 코딩 에이전트의 결합을 통해 단 20분 만에 완수되는 수준에 이르렀습니다.[1]
이러한 혁신을 이끄는 기술적 중추는 전체 작업을 지향성 비순환 그래프(DAG)로 추상화하여 코드 구현(impl), 테스트 설계(tests), 보안 검토(security_review) 등의 프로세스를 병렬 독립 노드로 처리하는 태스크 제어 아키텍처입니다.[3]
여기에 더해 터미널과 지속적 통합(CI) 파이프라인에서 직관적으로 허깅페이스 인프라를 호출할 수 있는 오픈소스 파이썬 라이브러리 및 CLI 도구들이 보급되면서 비개발자 직군도 자연어로 프로토타입을 손쉽게 제작하는 시대가 열렸습니다.[1, 4]
DAG 기반 태스크 제어 아키텍처란?
DAG는 Directed Acyclic Graph의 약자로, 작업 흐름을 순환이 없는 방향 그래프로 표현하는 방식입니다.
코딩 에이전트에서는 구현, 테스트, 보안 검토, 문서화 같은 작업을 독립 노드로 나누고, 선후 관계가 있는 작업만 연결해 병렬 실행과 실패 지점 추적을 쉽게 만듭니다.
자율성의 역풍: 에이전트 폭주 리스크와 다층 검증 격자망
자율성에 대한 의존도가 높아질수록 비결정론적 시스템의 부작용 또한 커지고 있습니다.[2, 3]
최근 현업에서 발생한 심각한 AI 자동화 오작동 사고는 무제한적인 코딩 에이전트 운영이 초래할 수 있는 보안적 한계를 생생하게 고발했습니다.[2]
악의적인 프롬프트 주입 공격을 통한 도구 하이재킹(Tool Hijacking)이나, 내부 데이터 무단 유출(Data Exfiltration), 그리고 에이전트가 만든 오류 섞인 코드를 무비판적으로 신뢰해 병합해 버리는 과도한 신뢰(Overreliance) 현상은 시스템 안정성을 심각하게 저해하는 요소입니다.[3]
이에 대응하기 위해 최신 아키텍처는 실시간 위험도 평가 게이트를 배치하는 다층 검증 격자(Verification Lattice)를 도입하는 추세입니다.[3]
에이전트가 처리 불가 영역을 감지하면 즉시 사람에게 제어권을 넘기는 ‘도움 요청(Ask-for-help)’ 트리거 기법이 표준 규격으로 채택되었으며, 오픈소스 기반 에이전트 프레임워크인 OpenClaw 시스템의 병목 현상과 풀 리퀘스트(PR)를 정밀 진단하는 ‘ClawSweeper’ 같은 특화 통제 툴들이 핵심 보안 인프라로 자리 잡고 있습니다.[2, 3]
Verification Lattice란?
Verification Lattice는 에이전트가 수행한 작업을 한 번에 신뢰하지 않고, 여러 검증 계층을 통과시키는 통제 구조입니다.
예를 들어 정책 검증, 보안 검사, 테스트 실행, 사람 승인 단계를 격자처럼 배치해 에이전트 폭주나 위험한 작업 실행을 줄입니다.
가성비의 종말, 소형언어모델(SLM)과 로컬 추론의 대중화
작지만 강력한 Specialized SLM의 반란
무조건 매개변수 규모를 늘리던 거대화 경쟁은 비용과 지연 속도라는 한계에 부딪혀 막을 내렸습니다.[1]
3B에서 7B 사이의 고도로 정제된 소형언어모델(SLM)은 수조 개의 파라미터를 가진 거대 모델 대비 연산 비용을 줄이면서도 의료 diagnosis나 금융 분석 같은 특수 도메인에서 오히려 압도적인 정밀도를 입증하고 있습니다.[1]
4B 파라미터 수준으로 경량화되었음에도 다국어 능력과 멀티모달 안전성 필터링을 완벽하게 통합해 낸 Nvidia의 Nemotron-3.5 Content Safety 모델의 등장은 이러한 성능 고도화를 상징하는 대표적 이정표입니다.[5]
이로 인해 네트워크 지연 없이 단말 내에서 50ms 이하로 작동해야 하는 실시간 금융 모형이나 모바일 헬스케어 기기 내부 탑재가 가능해졌습니다.[1]
$1,999달러의 하드웨어가 로컬 AI 혁신의 표준이 된 비결
이러한 경량화 모델들의 활성화는 개인용 하드웨어의 눈부신 하드웨어 최적화 아키텍처와 시너지를 내고 있습니다.[6, 7]
과거에는 거대 모델을 한번 테스트하기 위해 값비싼 고성능 그래픽 카드를 구매하거나 막대한 비용의 클라우드 인프라를 빌려 써야 했지만, 이제는 48GB 통합 메모리(Unified Memory)를 장착한 Mac Mini M4 Pro 단 한 대만으로도 Q4 양자화가 적용된 Llama 3.1 70B 모델을 부드럽게 구동할 수 있습니다.[6, 7]
Apple의 통합 메모리 구조는 CPU와 GPU가 물리적으로 완벽히 동일한 메모리 주소 영역을 지연 시간 없이 공유하기 때문에 PCIe 슬롯을 거칠 때 발생하는 성능 병목을 근본적으로 제거합니다.[7]
M4 Pro 기준 약 273 GB/s의 압도적인 대역폭을 유지하면서도 단지 30W 안팎의 전력만 소비하는 극한의 전력 효율성을 달성했습니다.[7]
최신 로컬 LLM 추론 기술 생태계의 도구별 특징
개발 환경에서 하드웨어 자원을 극대화하기 위해 폭넓게 조합하여 활용되는 대표적인 추론 엔진들의 특성을 구체적으로 분류해 보았습니다.[6]
| 로컬 추론 도구명 | 핵심 호환 포맷 | 주요 장점 및 차별성 | 치명적인 제약 사항 및 한계 |
|---|---|---|---|
| Ollama | GGUF | 한 줄의 명령어로 즉각 실행 가능한 높은 접근성, OpenAI/Anthropic 규격 API와 완벽 호환 | Safetensors나 오리지널 PyTorch 가중치를 사용하기 위해서는 별도의 Modelfile 기반 수동 변환 과정이 필요함 |
| LM Studio | GGUF, MLX, Safetensors | 시각적 GUI 제공, 허깅페이스 원클릭 다운로드 연동, 모델 성능 교차 비교가 용이한 스플릿 뷰 채팅 지원 | EXL2나 GPTQ 같은 GPU 가속 전용 압축 규격을 정식 지원하지 않음 |
| vLLM | GPTQ, AWQ, FP8, Safetensors | PagedAttention 및 Speculative Decoding 기법을 통한 대규모 동시 요청 처리의 독보적 고성능 | 설정 구성이 매우 복잡하여 대단위 GPU 전용 서버 가상화 환경에만 적합함 |
| llama.cpp | GGUF | 범용 시스템 아키텍처에 독립적인 호환성, CPU 환경에서 이끌어낼 수 있는 최고 성능 보장 | 세밀한 설정을 다루기 위한 CLI 제어 숙련도가 높게 요구됨 |
| Exo | 분산형 포맷 | 단말 여러 대를 피어투피어(P2P)로 결합하여 하나의 가상 메모리 풀처럼 작동시키는 분산 아키텍처 | 로컬 유무선 네트워크 상태에 따라 연산 간 지연 편차가 심하게 나타남 |
이처럼 인지도가 뛰어난 툴들을 묶어 ‘LM Studio로 신규 오픈 모델을 빠르고 편하게 분석하고, Ollama로 로컬 통합 API 환경을 연동한 뒤, 프로덕션 전환 시점에 vLLM의 성능을 활용해 처리량을 확보하는’ 3단계 툴체인이 정석으로 굳어졌습니다.[6]
다만 상용 클라우드 진영인 Anthropic과 Google이 OpenClaw 등 외부 에이전트 프로그램에 자사 API를 무차별 연동하여 과부하를 주는 행위를 약관상 금지하고 단속하기 시작했기 때문에, 하이브리드 아키텍처를 세우는 아키텍트들의 영리한 API 계약 관리가 강하게 수반되어야 합니다.[7]
GGUF, Safetensors, GPTQ, AWQ는 왜 중요한가?
이들은 로컬 LLM을 저장하거나 압축·실행하기 위한 모델 포맷 또는 양자화 방식입니다.
어떤 포맷을 쓰느냐에 따라 Ollama, LM Studio, vLLM, llama.cpp 같은 추론 도구와의 호환성, 메모리 사용량, 속도, 정확도가 달라집니다.
PagedAttention과 Speculative Decoding이란?
PagedAttention은 GPU 메모리를 더 효율적으로 관리해 여러 요청을 동시에 처리하기 쉽게 만드는 기법입니다.
Speculative Decoding은 작은 모델이 먼저 후보 토큰을 예측하고 큰 모델이 이를 검증하는 방식으로, 추론 속도를 높이는 데 사용됩니다.
RAG 아키텍처의 진화
지식 그라운딩을 가르는 파편화된 기술 노선과 최적화 딜레마
기업 내부의 축적된 도큐먼트를 기반으로 인공지능 답변의 신뢰도를 보정하는 검색 증강 생성(RAG) 아키텍처는 가성비, 연산 속도, 그리고 의미론적 정확도 사이의 타협점에 따라 매우 복잡한 세부 분기 구조를 가지게 되었습니다.[8]
단 한 번의 벡터 서치와 호출로 구성되는 Naive RAG 방식은 단 몇 시간 만에 프로토타입을 뽑아낼 수 있고 응답 속도가 대단히 빠르지만, 여러 페이지에 분산되어 존재하는 지식의 교차 관계를 분석하는 작업에는 완전히 무력합니다.[8]
반면 에이전트가 논리적 순회 과정을 거치며 정보를 끝없이 다시 찾아내 검증하는 Agentic RAG 방식은 정확도가 높은 대신 연산 지연 시간이 심각하게 늘어나 실시간 UI에 부적합하다는 단점을 드러냅니다.[8]
비즈니스 시나리오별 핵심 RAG 아키텍처의 비용-효과 비교 분석
다양하게 파편화된 최신 RAG 기법들의 구체적인 특성과 성과 지표는 다음과 같이 분류됩니다.[8]
| RAG 아키텍처 분류 | 쿼리당 추정 소요 비용 | 일반적인 응답 지연 속도 | 최고의 효율을 내는 비즈니스 유스케이스 | 치명적인 도입 극복 과제 |
|---|---|---|---|---|
| Naive RAG | 대략 $0.001 | 100ms∼500ms | 사내 단순 복리후생 규정 검색, 개별 팩트 중심 질의 | 정보가 여러 문서에 나뉘어 있을 시, 맥락 통합 불가 |
| Agentic RAG | Naive 대비 약 10배 | 2s∼10s 이상 | 복잡한 연구 논문 교차 검증 및 지식 자기 교정 루프 가동 | 비결정론적 반복 호출로 인한 비용 예측 불가능성 |
| GraphRAG | Naive 대비 약 3 – 5배 | 그래프 트래버스 지연 존재 | 전체 지식창고 내 개념 간의 다중 홉(Multi-hop) 상관성 추출 | 대단히 무겁고 비싼 초기 엔티티 그래프 인덱싱 구조 |
| Adaptive RAG | 사용자 질의 난이도 비례 | 질의 동적 분기 최적화 | 대규모 사용자가 다양한 성격의 난이도 높은 질문을 할 때 | input 쿼리를 정밀하게 해석할 수 있는 분류 모델 고도화 필요 |
이를 극복하기 위해 설계된 ‘Adaptive RAG(적응형 RAG)’ 모델은 input 쿼리의 난이도를 초기에 스마트하게 분류하여 가벼운 팩트 체크 질문은 Naive/Advanced RAG 라인으로 빼내어 빠르게 처리하고, 상호 유기적 관계 탐색이 꼭 필요한 질문에 한해서만 고비용의 GraphRAG나 Agentic RAG 파이프라인으로 선택적 분기 처리를 수행합니다.[8]
이와 함께 하이브리드 검색 방식을 채택했을 때 문서 수집 성능 지표는 정밀도(Precision)가 0.68에서 0.87로, 재현율(Recall) 역시 0.72에서 0.91로 눈에 띄게 개선되었습니다.[8]
또한 우선적으로 수천만 건의 문서 풀에서 상위 50~200개 문서 가중치를 고속 검색한 뒤, 100K 이상의 대단위 컨텍스트 영역으로 한 번에 넘겨 기계 독해를 수행하는 ‘RAG-then-Long-Context’ 형태 역시 리드 엔지니어들 사이에서 실질적인 비용 절감 아키텍처로 낙점받았습니다.[8]
엔터프라이즈 컴플라이언스와 공급망 보안
2026년 6월, JFrog Artifactory 강제 마이그레이션이 몰고 온 격랑
사내 개발망 내부로 유입되는 모델 가중치를 안전하게 검증하기 위해 JFrog Artifactory 프록시를 설치해 운영하는 기업 보안 및 인프라 담당 부서는 당장 이번 달 인프라 마이그레이션 상태를 완벽히 재점검해야 합니다.[9]
2026년 6월을 기점으로 기존의 구형 레거시 “Hugging Face” 레이아웃 지원이 원천 종료되며, 한 단계 진화한 ‘Machine Learning 리포지토리 레이아웃’ 규격으로의 강제 업그레이드가 시행되었기 때문입니다.[9]
이 새로운 ML 레이아웃 구성을 준수해야만 대규모 고가중치 파일 전송 시 스토리지 중복 점유율을 제로 수준으로 수렴해 주는 Xet 프로토콜을 온전히 운용할 수 있게 되며, 사내 가상(Virtual) 리포지토리 연동 또한 장애 없이 온전한 형태로 통합 가동됩니다.[9]
SOC 2 및 ISO 27001 통과를 가르는 요금제 선택 가이드
엄격한 서드파티 소프트웨어 보안 심사와 IT 지배구조(IT Governance) 실사를 통과하기 위해서는 사용 중인 허깅페이스의 서브스크립션 등급 선택이 생각보다 결정적인 차이를 유발합니다.[10]
허깅페이스 사 자체의 SOC 2 Type II 인증 여부와 무관하게, 외부 감사인에게 시스템 자산 전반의 통제권과 사내 유출 방지 이력을 입증해야 하는 책임은 전적으로 기업 내부의 ML 개발 조직에 귀속되기 때문입니다.[10]
| 컴플라이언스 체크리스트 정보 | Free 등급 | Team 등급 | Enterprise 등급 | Enterprise Plus 등급 |
|---|---|---|---|---|
| 감사 증적 로그 보관 | 미지원 | 생성, 삭제, 멤버 변동 등 기초 로그 아카이빙 | 모델 리소스 그룹 및 미세 조정 토큰 변동 추적 | 개별 파일의 다운로드 세부 행위 정보 제공 |
| 중앙 집중식 ID 거버넌스 | 개인 계정 | 기본적인 SSO 기능 제공 | 자동화 SCIM 기반의 입사/퇴사 유저 권한 제어 | 지정 Identity Provider 연동만 허용하는 강제 통제 |
| 유출 차단 제어(leakage prevention) | 통제 수단 없음 | 조직 소속 저장소의 외부 유출 금지 | 사내 IP 대역 관리 및 외부 이전 탐지 허용 | 사내 개인 계정을 사용하는 모델 외부 유출 완전 차단 |
| 지리적 데이터 보관 법률(GDPR) | 미국 범용 리전 | 가상 리소스 분할 | EU 데이터 거주성 등 보장 리전 직접 지정 | 전용 엔터프라이즈 전용선 및 완전 통제 스토리지 제공 |
통제 증적을 통과하려는 기업들에 무료 티어는 사실상 무용지물이며, 최소 Team 요금제를 갖춰야 감사 로그를 정상적으로 제출할 수 있습니다.[10]
한층 고도화된 정보 자산 보호를 원한다면 직원의 무단 전재 및 개인 계정 업로드를 통제할 수 있는 Enterprise Plus 라이선스와 함께, 전용 내부 모델 게이트웨이를 설계하는 것이 필수적인 선택입니다.[9, 10]
클라우드 인프라 아키텍처의 적합성 판단 요점
추가적으로, 모델이 민감한 질의에 거부 의사를 밝힐 때 사용자를 지나치게 가르치려 들거나 불쾌감을 유발하지 않도록 섬세하게 답변을 다듬는 Targeted Refusal Modification(TRM, targeted refusal modification) 기법은 최근 안전 정렬 기법의 중요한 축으로 각광받고 있습니다.[11]
이러한 정밀 정렬 모델들을 실제 인프라에 안착시킬 때, 기업 개발 부서는 고성능 자원이 필요할 때에만 H100 GPU 가상 컨테이너를 가동하고 미가동 시 과금을 완벽히 멈춰주는 Modal 샌드박스 기술과 Fly.io의 요청 기반 탄력성 제어 아키텍처를 유기적으로 조합하여 클라우드 운용 효율성을 극대화해야 합니다.[12]
참고자료
- AI 2026 — The 9 trends that will EXPLODE this year! – Hugging Face, https://huggingface.co/blog/RDTvlokip/the-9-trends-that-will-explode-this-year
- WEEKLY AI HOT 5 – Mossland Blog – Medium, https://medium.com/mossland-blog/weekly-ai-hot-5-5102a5746d55
- 2026 Agentic Coding Trends – Implementation Guide (Technical) – Hugging Face, https://huggingface.co/blog/Svngoku/agentic-coding-trends-2026
- Dell Enterprise Hub at Dell Tech World 2026: new models, new platforms, faster to production – Hugging Face, https://huggingface.co/blog/balaatdell/dell-enterprise-hub-at-dell-tech-world-2026
- Nemotron 3.5 Content Safety: Customizable Multimodal Safety for Global Enterprise AI, https://huggingface.co/blog/nvidia/nemotron-3-5-content-safety
- Local LLM Inference in 2026: The Complete Guide to Tools, Hardware & Open-Weight Models – Starmorph, https://blog.starmorph.com/blog/local-llm-inference-tools-guide
- Best Mac Mini for Running Local LLMs and OpenClaw: Complete Pricing & Buying Guide (2026) – Starmorph, https://blog.starmorph.com/blog/best-mac-mini-for-local-llms
- RAG Techniques Compared: A Practical Guide to Retrieval Augmented Generation in 2026, https://blog.starmorph.com/blog/rag-techniques-compared-best-practices-guide
- Hugging Face on JFrog Artifactory: An Enterprise Guide (and What Changes in June 2026), https://huggingface.co/blog/jeffboudier/jfrog-artifactory-june-2026
- How to Comply with SOC 2 and ISO 27001 with Hugging Face: A Practical Guide to AI Model Supply Chain Governance, https://huggingface.co/blog/jeffboudier/soc2-iso27001-ai-compliance-guide
- Targeted Refusal Modification (TRM): Precision Separation of Safety and Harm in Large Language Models – Hugging Face, https://huggingface.co/blog/senaro/trm-safety-alignment
- AI Agent Deployment: Cloud Platforms Compared for Ephemeral, Long-Running, and GPU Workloads (2026) – Starmorph, https://blog.starmorph.com/blog/ai-agent-deployment-cloud-platforms-compared