
파이썬의 기초 문법 중 하나인 문자열 함수 !! 저는 파이썬 문자열 함수는 약 4년 전에 파이썬 처음 공부할 때 빼고는 본 적이 없습니다.
그런데 알고리즘 문제를 풀다 보니 다시 한 번 정리하면 좋을 것 같아서 몇 가지 정리해보았습니다.
f-string : 파이썬 문자열 포맷팅
문자열 안에서 변수 값을 간편하게 삽입할 수 있습니다.
f-string은 문자열 앞에 f를 붙여서 사용합니다. 중괄호 {} 안에 변수나 표현식을 넣어 해당 값을 문자열에 삽입합니다.
기본 사용법
name = "Alice"
age = 30
# f-string 사용 예제
greeting = f"안녕하세요, 제 이름은 {name}이고, 나이는 {age}살입니다."
print(greeting)f-string 디버깅
print(f'{변수명=}')파이썬 3.8이상 부터 가능한 기능입니다.변수명= 이런식으로 적으면 자동으로 아래와 같이 출력해줍니다.
a = [1, 2, 3, 4]
b = {1: [0, 0, 1], 2: [1, 0, 0]}
print(f"{a=} // {b=}") # a=[1, 2, 3, 4] // b={1: [0, 0, 1], 2: [1, 0, 0]}소수점 지정
소수점 이하 자릿수를 제한하거나 정수로 표시할 수 있습니다.
PI = 3.141592
print(f"파이는 {PI:.2f}") # 파이는 3.14참고. 실수를 정수로 표현하는 법
import math
float_num = 3.141592
print(math.floor(float_num)) # 3
print(f"{float_num:.0f}") # 3
print(int(float_num)) # 3
print(round(float_num,0)) # 3.0
print(float_num//1) # 3.0조건문 반복문 사용
is_adult = True
# 조건문과 반복문 사용 예제
message = f"당신은 {'성인' if is_adult else '미성년자'}입니다."
print(message)문자열 뒤집기 (회문)
strs1 = "KOREA"
strs2 = strs1[::-1]
print(f"{strs1=}, {strs2=}") # strs1='KOREA', strs2='AEROK'count(): 특정 문자열 등장 횟수 세기
count() 함수는 특정 부분 문자열이 문자열 내에서 몇 번 등장하는지 세어줍니다.
sentence = "She sells seashells by the seashore."
count_sea = sentence.count("sea")
print(f"'sea' 등장 횟수: {count_sea}")반복 문자열에서 count() 함수 사용시 유의점
count() 함수는 한 번 카운트한 문자열은 제외하고 그 다음 문자열부터 다시 count를 시작합니다. 때문에 아래와 같이 011101110에서 01110은 2개임에도 1개로 count를 해줍니다.
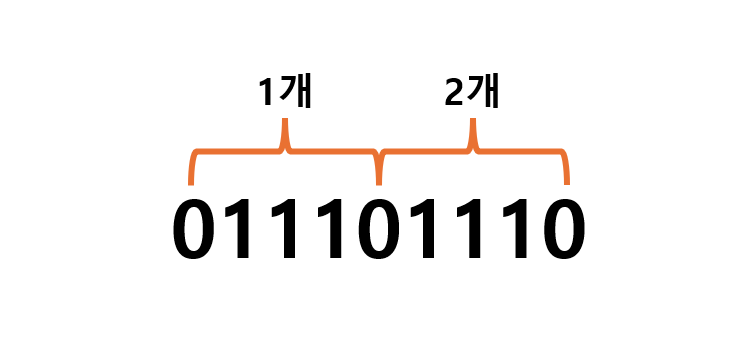
print('011101110'.count('01110')) #1이를 해결하기 위해서는 결국 반복문으로 탐색을 해야 합니다.
cocococo 에서 coco 문자열의 수를 찾는다고 하면 아래와 같이 2가지 경우로 찾을 수 있습니다.

strs = "cocococo"
find_str = "coco"
iter_count = 0
for i in range(len(strs)-len(find_str)+1):
substr = strs[i:i+len(find_str)]
if substr == find_str:
iter_count += 1
print(f"{iter_count=}") # iter_count=3
print(f"{strs.count(find_str)=}") # strs.count(find_str)=2find() : 부분 문자열 위치 찾기
find() 함수는 특정 부분 문자열이 문자열 내에서 처음으로 나타나는 위치의 인덱스를 반환합니다.
만약 찾지 못할 경우 -1을 반환합니다.
찾지 못할 경우 0이 아닌 -1을 반환하는 것에 유의해야 합니다.
word = "apple"
index_a = word.find("a")
print(f"'a'의 첫 등장 위치: {index_a}")replace() : 문자열 치환
replace() 함수는 문자열 내의 특정 부분 문자열을 다른 문자열로 치환합니다.
sentence = "I like programming with Python."
new_sentence = sentence.replace("Python", "Java")
print(f"치환 결과: {new_sentence}")join() : 문자열 리스트 결합
join() 함수는 문자열 리스트를 특정 구분자를 이용해 결합합니다.
words = ["Python", "is", "awesome"]
combined_string = " ".join(words)
print(f"결합 결과: {combined_string}")index() : 부분 문자열 위치 찾기
index() 함수는 특정 부분 문자열이 문자열 내에서 처음으로 나타나는 인덱스를 반환합니다.
str.index(sub, start, end)str: 검색 대상이 되는 문자열sub: 찾고자 하는 부분 문자열start(옵션): 검색을 시작할 인덱스. 기본값은 0입니다.end(옵션): 검색을 끝낼 인덱스. 기본값은 문자열의 길이입니다.
인자를 ‘찾고자 하는 문자열’ 하나만 입력하면 문자열 내에서 가장 처음으로 나오는 인덱스만 찾을 수 있습니다.
반면에 start, end에 인자를 넣어주면 원하는 범위의 문자열에서 인덱스를 찾을 수 있습니다.
# 문자열 정의
text = "Python is powerful and Python is easy."
# 'is'의 첫 번째 등장 위치 찾기
index1 = text.index('is')
print(f"첫 번째 'is'의 인덱스: {index1}")
# 두 번째 'is'의 위치 찾기 (시작 인덱스 지정)
index2 = text.index('is', index1 + 1)
print(f"두 번째 'is'의 인덱스: {index2}")
# 특정 범위 내에서 검색
index3 = text.index('is', 15, 30)
print(f"15부터 30 사이에서 'is'의 인덱스: {index3}")