
서브쿼리 vs JOIN : 서브쿼리와 JOIN 문은 데이터베이스에서 정보를 추출하는 두 가지 주요 방법입니다. 성능 차이는 데이터 양, 인덱스의 존재 여부, 데이터베이스 종류 등에 따라 다를 수 있습니다.
서브쿼리
SELECT *
FROM employees
WHERE department_id = (SELECT department_id FROM departments WHERE department_name = 'Sales');서브쿼리는 메인 쿼리의 결과에 따라 서브 쿼리가 실행됩니다. 매번 서브쿼리를 실행하므로 데이터베이스 부하가 발생할 수 있습니다.
작은 데이터셋이나 적은 수의 행에 대한 필터링에서는 효과적일 수 있습니다.

서브쿼리를 사용하면 코드의 가독성이 떨어지지 않고, 복잡한 조건을 적용하기 용이합니다.
JOIN
JOIN은 두 개 이상의 테이블 간에 관련된 열을 결합하여 결과를 생성합니다. JOIN은 대개 테이블 간의 관계를 활용하므로 인덱스가 적절하게 설정되어 있다면 효율적입니다.
대량의 데이터셋이나 여러 테이블 간의 연결이 많은 경우에 유용합니다.
INNER JOIN, LEFT JOIN, RIGHT JOIN 등 다양한 JOIN 종류가 있어 조인 방식을 선택하여 데이터 추출이 가능합니다.
평소에는 서브 쿼리 보다는 JOIN이 속도가 빠르겠지만, 데이터 수는 적으면서 중복된 데이터가 많을 경우에는 지연 평가 원리를 사용하는 EXISTS 문이 빠를 수도 있습니다.
지연 평가 원리
EXISTS의 경우 서브 쿼리를 만족하는 레코드를 처음 만나는 순간 true이므로 서브쿼리를 더 이상 진행하지 않는 것을 지연 평가 원리라고 합니다.
SELECT employees.*, departments.department_name
FROM employees
JOIN departments ON employees.department_id = departments.department_id
WHERE departments.department_name = 'Sales';서브쿼리 -> JOIN 대체
서브쿼리를 JOIN 으로 대체하는 예를 위해 다음 2 테이블이 있다고 가정해보겠습니다.
<product> 테이블

<sale> 테이블
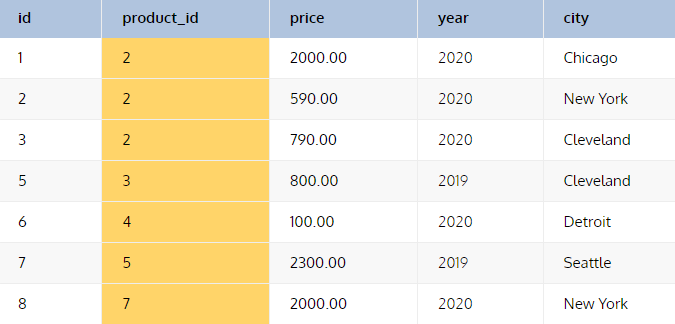
Scalar 서브쿼리인 경우
스칼라 서브쿼리(Scalar Subquery)는 결과로 스칼라 값을 반환하는 서브쿼리를 말합니다.
스칼라 값은 단일한 값을 가지며, 행과 열이 아닌 하나의 값을 나타냅니다.
-- 서브쿼리
SELECT name, cost
FROM product
WHERE id=(SELECT product_id
FROM sale
WHERE price=2000
AND product_id=product.id
);
-- JOIN 문으로 대체
SELECT p.name, p.cost
FROM product p
JOIN sale s ON p.id=s.product_id
WHERE s.price=2000;IN 연산자 서브쿼리인 경우
팔린 제품의 이름과 가격을 얻고 싶다고 가정했을 때, 서브쿼리와 조인문은 아래와 같습니다.
-- 서브 쿼리
SELECT name, cost
FROM product
WHERE id IN (SELECT product_id FROM sale);
-- JOIN 문으로 대체
SELECT DISTINCT p.name, p.cost
FROM product p
JOIN sale s ON s.product_id=p.id;JOIN이 inner join이기 때문에 product 테이블과 sales 테이블 사이에 ID가 동일한 게 없는 경우에는 아무 것도 반환하지 않습니다.
여지서 DISTINCT 키워드로 중복을 제거한 것을 주목해야 합니다.
서브쿼리의 IN, NOT IN에서 JOIN으로 변환 시 DISTINCT는 종종 필수적입니다.
NOT IN 연산자 서브쿼리인 경우
팔리지 않은 상품 레코드를 원하다고 가정하면 서브쿼리와 JOIN문은 아래와 같습니다.
-- 서브 쿼리
SELECT name, cost
FROM product
WHERE id NOT IN (SELECT product_id FROM sale);
-- JOIN 문으로 대체
SELECT DISTINCT p.name, p.cost
FROM product p
LEFT JOIN sale s ON s.product_id=p.id
WHERE s.product_id IS NULL;IN 연산자 서브쿼리의 변환과 마찬가지로, 중복제거를 위해 DISTINCT를 사용합니다.
NOT IN이 있는 서브쿼리를 JOIN으로 변환할 때는 LEFT JOIN을 사용합니다.
LEFT JOIN을 통해서 sale 테이블에 없는 product_id도 가져옵니다. 그 후 prodcut_id가 NULL인 레코드를 선택하면 NOT IN 서브쿼리와 동일한 결과를 반환합니다.
EXISTS 혹은 NOT EXISTS과 관련된 서브쿼리인 경우
2020년에 팔리지 않은 상품 레코드를 가져온다고 가정하면 서브쿼리와 JOIN문은 아래와 같습니다.
-- 서브쿼리
SELECT name, cost, city
FROM product
WHERE NOT EXISTS ( SELECT id
FROM sale WHERE year=2020 AND product_id=product.id );
-- JOIN 문으로 대체
SELECT p.name, p.cost, p.city FROM product p
LEFT JOIN sale s ON s.product_id=p.id
WHERE s.year!=2020 OR s.year IS NULL;메인 쿼리의 각 product에서 서브쿼리는 2020년도 레코드를 선택합니다. 만일 서브쿼리에서 반환하는 게 없다면 NOT EXISTS는 true를 반환합니다.
NOT EXISTS가 있는 서브쿼리를 JOIN을 변환하기 위해 product 테이블과 sale 테이블을 LEFT JOIN으로 연결합니다.
이것은 한 번도 팔리지 않은 제품의 결과도 포함하게 됩니다.
WHERE 절에서 2020년에는 팔리지 않거나(s.year!=2020) 한 번도 팔린 적 없는 조건(s.year IS NULL)을 겁니다.
JOIN이 Subquery를 대체할 수 없는 경우
GROUP BY를 사용하여 집계 값을 계산하는 서브쿼리가 FROM 절에 들어가는 경우
SELECT city, sum_price
FROM
(
SELECT city, SUM(price) AS sum_price FROM sale
GROUP BY city
) AS s
WHERE sum_price < 2100;서브쿼리 결과 집계 값이 WEHRE 절에 들어가는 경우
SELECT name FROM product
WHERE cost<(SELECT AVG(price) from sale);서브쿼리 vs JOIN 요약
성능 차이는 데이터베이스 최적화, 인덱스 사용 여부, 쿼리 작성 방법 등에 따라 다르므로 특정 상황에서는 JOIN이 더 효율적일 수 있고, 다른 상황에서는 서브쿼리가 더 효율적일 수 있습니다.
특정 연산(GROUP BY, 집계함수, DISTINCT)을 위해서는 JOIN문 아닌 서브쿼리를 사용해야 할 때도 있습니다.

