Flume 개념 : Apache Flume는 대규모 로그 데이터를 효율적으로 수집, 집계, 이동시키기 위한 분산 시스템입니다.
다양한 곳에 위치한 서버에서 데이터를 취해 데이터의 플로우를 구성하여 데이터를 통합하여 목적지로 전달해줍니다.
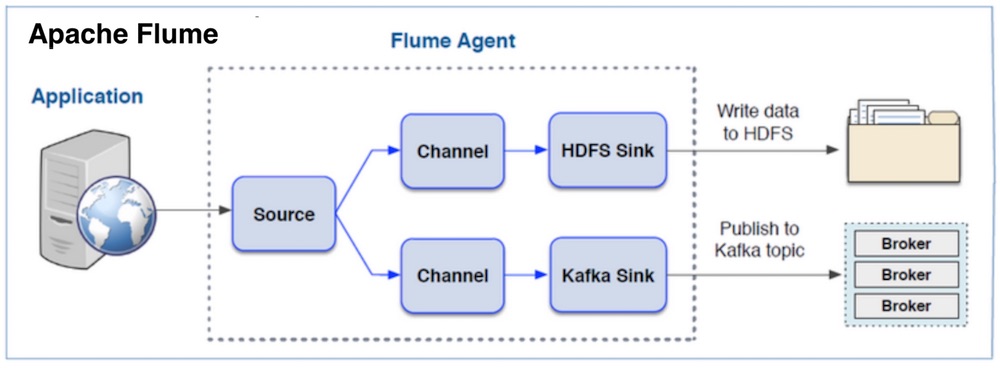
Flume 데이터 흐름 구성요소
“Flume 개념”은 Flume의 데이터 흐름을 구성하는 세 가지 주요 구성 요소 Source, Channel, Sink 가 가장 중요합니다.
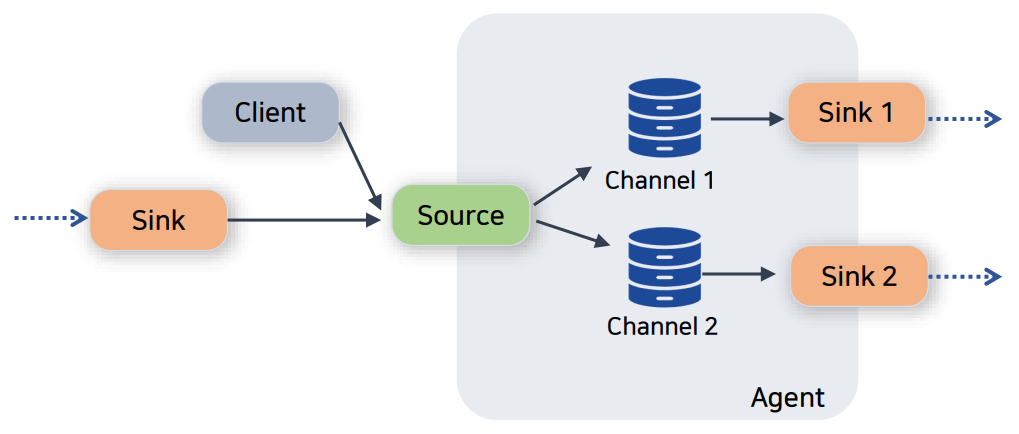
각 구성 요소의 역할은 다음과 같습니다
Source
데이터를 수집하는 시작 지점.
- 기능: 외부 시스템(예: 웹 서버, 로그 파일, 소켓 등)에서 데이터를 읽어 Channel로 전송.
- 예시: HTTP Source, Exec Source, Spooling Directory Source.
Channel
Source와 Sink 사이에서 데이터를 버퍼링하는 중간 저장소.
- 기능: Source에서 받은 데이터를 임시로 저장하고, Sink로 전달할 때까지 유지.
- 예시: Memory Channel, File Channel, JDBC Channel.
Sink
데이터를 최종 목적지로 보내는 종착 지점.
- 기능: Channel에서 데이터를 읽어 외부 저장소(예: HDFS, HBase, Kafka 등)로 전송.
- 예시: HDFS Sink, HBase Sink, Kafka Sink.
이들 구성 요소는 데이터 흐름의 각 단계를 담당하며, Flume 에이전트 내에서 서로 연결되어 데이터를 효과적으로 이동시키고 처리합니다.
Flume에서 수집되고 저장할 수 있는 데이터 종류
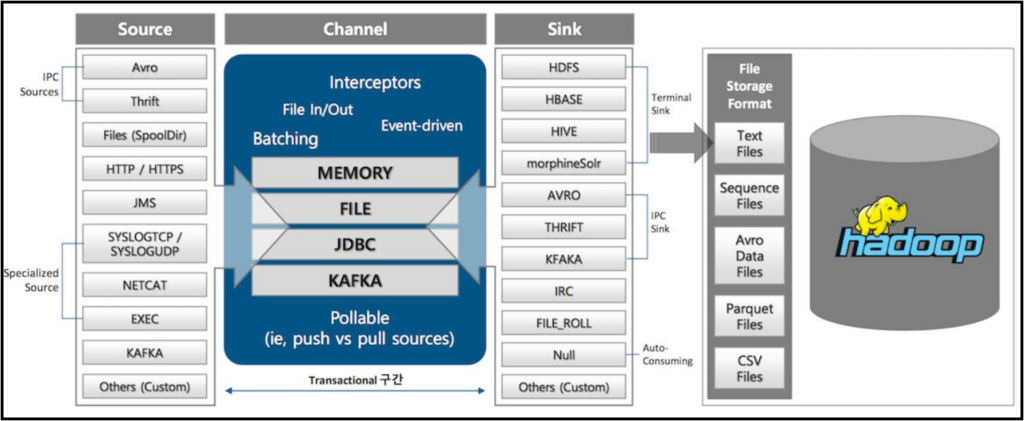
소스로 수집되는 다양한 데이터 형식
Avro: 데이터 직렬화 시스템으로, 다양한 프로그래밍 언어로 데이터를 쉽게 읽고 쓸 수 있음
Thrift: 여러 프로그래밍 언어를 지원하는 Thrift 통신을 통해 Flume 에이전트에 직접 데이터를 가져옴
Files (SpoolDir): 디렉터리의 로그 파일
HTTP/HTTPS: HTTP 또는 HTTPS 엔드포인트의 데이터
JMS: Java 메시지 서비스 데이터
SYSLOGTCP/SYSLOGUDP: TCP 또는 UDP를 통한 Syslog 데이터
NETCAT: 네트워크 소켓에서 실시간 데이터를 캡처
EXEC: 사용자 지정 명령이나 스크립트를 실행하여 로그 데이터를 생성하고 해당 출력을 Flume 에이전트에서 수집
KAFKA: Kafka의 분산 메시지 스트림을 Flume 관리 데이터 흐름에 통합
Flume Dataflow 형태 1. Multi-Agent
두개 이상의 서버에 각각 Flume Agent가 설치하여 Flume을 구성할 수도 있습니다.
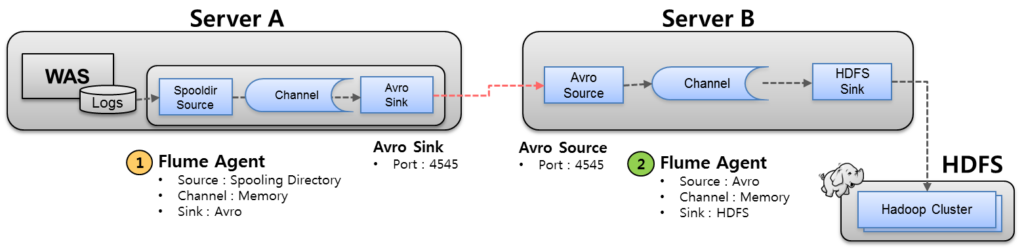
서버 A(수집 에이전트가 있는 WAS 서버)
- Spooling Directory Source: 디렉터리에서 새 로그 파일을 모니터링하고 읽습니다.
- Memory Channel: 로그 데이터를 메모리에 임시 저장합니다.
- Avro Sink: Avro 통신을 통해 서버 B에 로그 데이터를 전송합니다.
서버B(별도 수집서버)
- Avro Source: Avro 통신을 통해 서버 A로부터 로그 데이터를 수신합니다.
- Memory Channel: 수신된 로그 데이터를 메모리에 임시 저장합니다.
- HDFS Sink: 수집된 로그 데이터를 HDFS에 저장합니다.
Multi-Agent 구성의 이점
위와 같이 2 대 이상의 서버로 구성하면 아래와 같은 이점이 있습니다.
부하 분산
로그 데이터를 다른 서버로 전송함으로써 WAS 서버는 HDFS에 직접 대용량 데이터를 쓰는 추가 작업에 부담을 주지 않습니다. 이렇게 하면 WAS 서버에서 실행되는 기본 애플리케이션이 로깅 작업의 영향을 받지 않습니다.
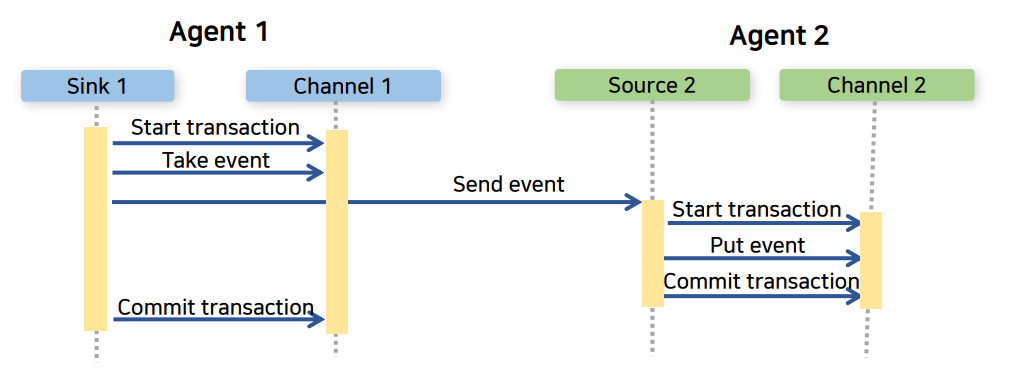
신뢰성
2개의 Agent에서 데이터를 주고 받을 때 Transaction을 통해 메시지를 잘 보내고 잘 받았다는 것을 확인해야지만 채널에서 버퍼로 잡고 있던 데이터를 놓아주도록 합니다.
이런 방식으로 데이터를 신뢰성을 보장해 줄 수 있는 것이죠.
확장성
로그 볼륨이 증가하면 추가 수집 서버(서버 B)를 추가하여 WAS 서버에 영향을 주지 않고 증가된 부하를 처리할 수 있습니다.
서버 B에 추가 싱크를 추가하여 Elasticsearch, Kafka 또는 기타 HDFS 클러스터와 같은 다른 시스템에 데이터를 저장하여 유연성과 확장성을 제공할 수 있습니다.
내결함성
로그 수집 작업과 저장 작업을 분리함으로써 서버 B의 HDFS 싱크 오류가 서버 A의 로그 생성 및 수집에 직접적인 영향을 미치지 않습니다.
보안
서버 B는 더욱 엄격한 보안 제어로 구성되어 인증된 데이터만 HDFS로 전송되도록 할 수 있습니다. 이러한 격리는 추가적인 보안 계층을 제공할 수 있습니다.
Flume Dataflow 형태 2. Consolidation
가장 일반적인 데이터 수집 구조로 여러 웹 서버로부터 데이터를 수집하기 위해 여러 agent를 설정 합니다.
여러 agent에서 하나의 agent로 데이터를 통합하는 구조입니다.
Consolidation agent가 마지막 저장 장치에 데이터를 전달 합니다.
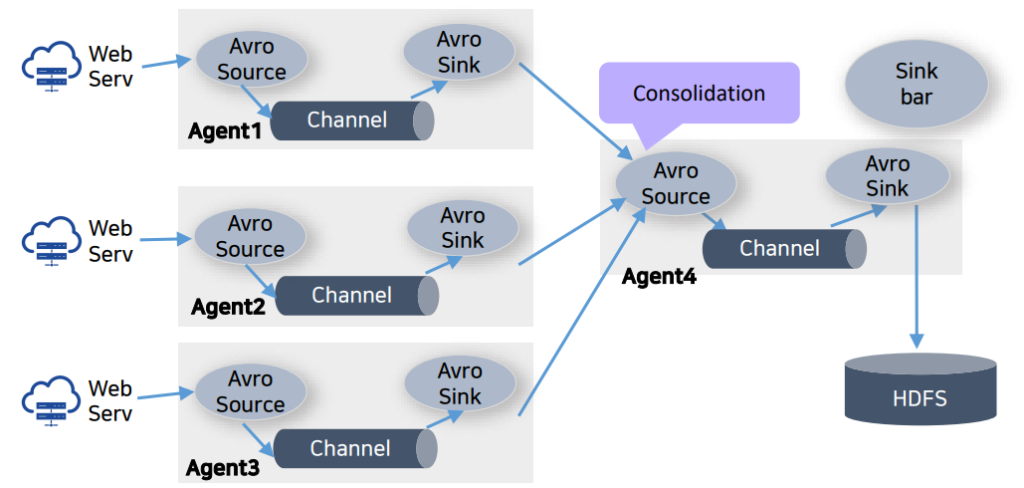
Consolidation 구성의 이점
Flume 데이터 흐름의 “통합” 방법은 여러 개의 작은 데이터 스트림을 보다 크고 관리하기 쉬운 단위로 결합하여 데이터 처리를 간소화하고 오버헤드를 줄이고 데이터 처리 및 전송 효율성을 향상시켜줍니다.
Flume Dataflow 형태 3. Multiplexing
하나 이상의 목적지에 데이터를 저장할 수 있도록 하는 흐름입니다.
Multiplexer를 정의하면 채널-싱크가 복사되어 원하는 곳으로 데이터를 전송하여 저장 가능 합니다.
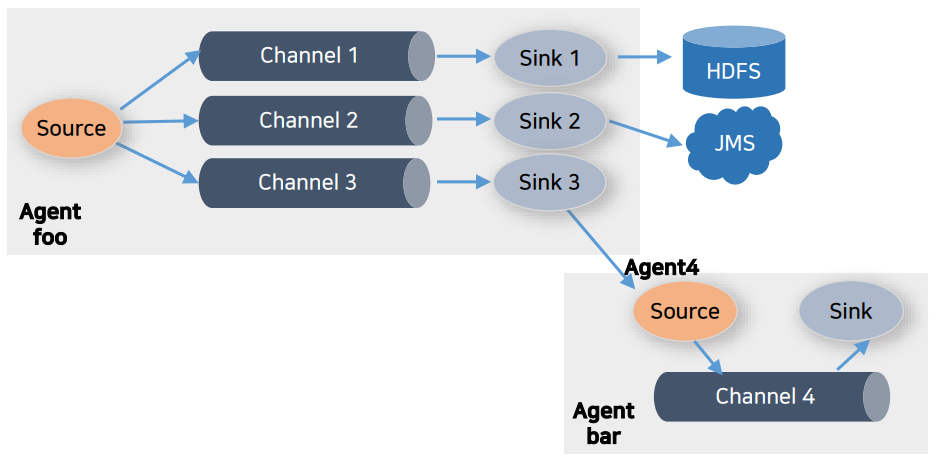
Flume Dataflow 형태 4. Fan-in / Fan-out
Flume은 하나의 소스로 부터 하나의 채널, 하나의 Sink로 이어지는 게 아니라 여러 Source로부터 여러 Sink로 이어지도록 구성할 수도 있습니다.
아래 그림과 같이 로그를 발생시키는 여러 서버들로 부터 수집을 하고, 용도에 맞게 여러 곳으로 이벤트를 전달 저장하는 구조는 아래와 같은 경우를 확인해주세요.
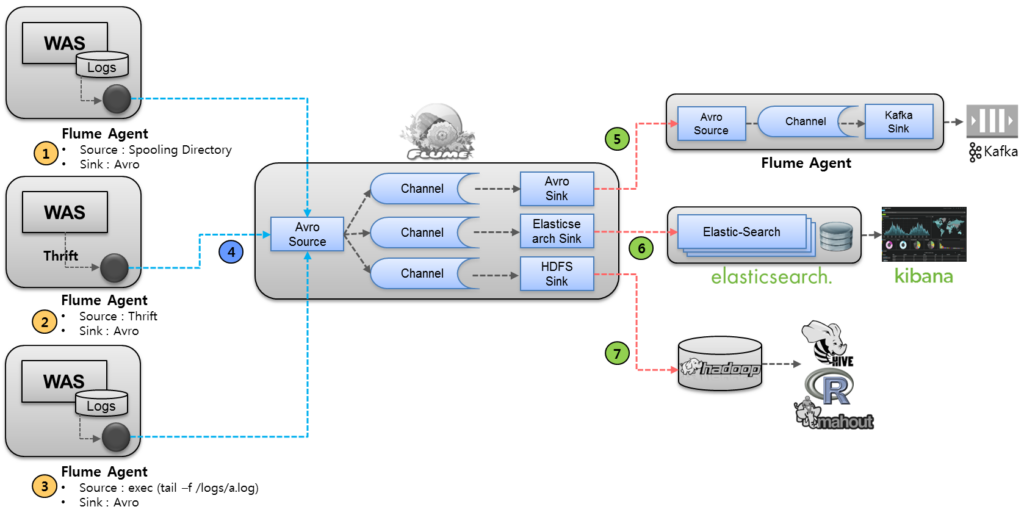
위와 같은 데이터 흐름을 Fan-in, Fan-out 구조라고 합니다.
Fan-in
여러 소스에서 단일 채널로 데이터를 전송 하여 다양한 소스의 로그를 통합할 수 있습니다.
- Spooling Directory Source : WAS의 Log 파일 위치의 디렉토리를 Spooling하여 파일이 만들어졌을때를 모니터링하여 수집
- Thrift Source : WAS에서 로그를 파일로 별도로 남기지 않고, Thrift 통신으로 직접 Agent에 발송하여 로그 수집
- Exec Source : WAS의 로그파일을 tailing하여 로그 수집
- Avro Source : 각 WAS에서 수집된 로그를 Avro 통신을 통해 로그를 중간 집적서버로 전송
Fan-out
단일 소스는 여러 채널이나 싱크로 데이터를 전송할 수 있으므로 다양한 목적을 위해 데이터를 여러 대상으로 배포할 수 있습니다.
- Avro Source를 통해 들어온 이벤트를 Channel selector를 통해 각각의 Channel로 전송
- Avro Sink : 또 다른 Agent 서버로 이벤트를 Avro 통신을 통해 전송하여, 해당 Agent는 Kafka Sink를 통해 분산 메시징 큐인 Kafka로 저장하여, 필요한 Application에서 메시지 가져갈 수 있게 준비함. 일반적으로 실시간 처리를 하기 위해 많이 활용 됩니다.
- Elasticsearch Sink : 오픈소스 검색엔진인 Elastic-Search 로 Sink하여 Kibana와 같은 로그 통계,모니터링을 통해 서비스 가능
- Hadoop Sink : 대용량 분산 저장을 위해 HDFS(Hadoop Distributed File System))로 저장하여, Hive,Pig,R,Mahout 등으로 배치 분석,기계어 학습 등에 활용
출처 & 참고하면 좋은 글
“Flume 개념” 을 잡는데 도움을 받은 글 입니다.
http://taewan.kim/post/flume_images
https://blogs.apache.org/flume/entry/flume_ng_architecture
