Apache Kafka 는 분산 이벤트 스트리밍 플랫폼입니다.
카프카는 Scala와 Java로 작성되었으며 LinkedIn 데이터 엔지니어에 의해 탄생 된 시스템이죠
실시간 데이터 파이프라인과 스트리밍 애플리케이션을 구축하는 데 사용되는데요. 이번에는 Kafka 동작에 대해 공부한 내용을 정리해보았습니다.
Publish-subscribe 메시징 시스템
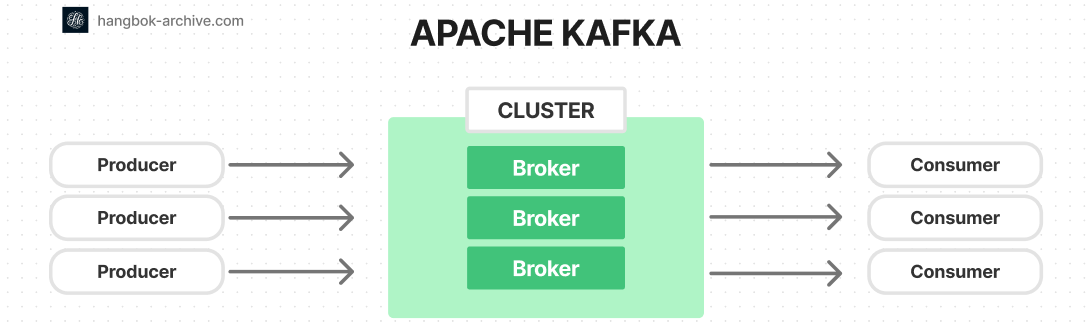
Apache Kafka는 publish-subscribe (pub-sub) 기반의 메시징 시스템 입니다.
pub-sub 시스템 이란?
pub-sub 시스템 이라는 것은 데이터 생산자 Producer가 받는 주체를 정하지 않은 채 우선 중간 다리 역할인 Broker에 publish를 하고, 데이터를 소비하는 Consumer가 이를 구독하는 체계를 뜻합니다.
Redis, RabbitMQ, AWS SQS 같은 서비스가 pub-sub 기반 서비스입니다.
이와 같은 메시징 시스템은 프로세스, 어플리케이션, 서버 사이에 메시지를 전달해주는 특징을 가지고 있습니다.
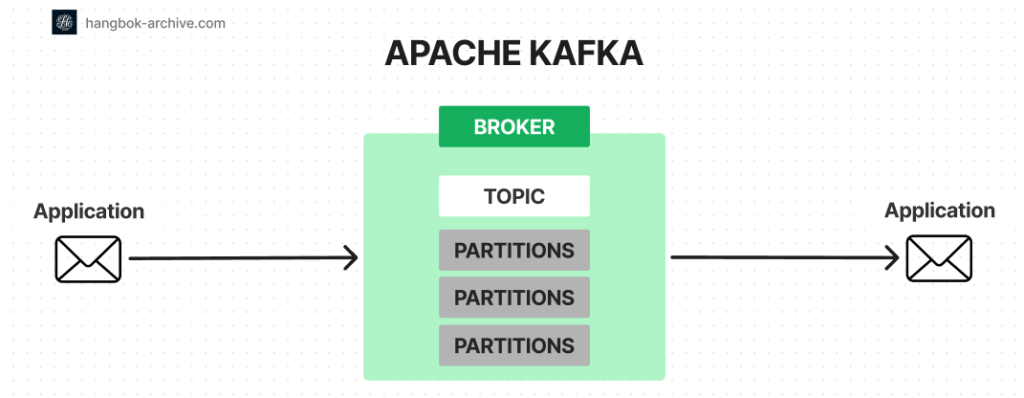
Kafka는 Topic(카테고리)를 정의하고 애플리케이션이 Topic에 레코드를 추가, 처리 및 재처리할 수 있는 소프트웨어입니다.
레코드는 byte array로 어느 포맷의 객체라도 저장할 수 있습니다.
레코드는 key, value, timestamp(optional), header(optional) 4가지 속성이 있습니다.
key-value에서 value는 어떠한 포멧도 가능합니다.
Kafka의 구성요소 요약
| 구성요소 | 개념 | 역할 |
|---|---|---|
| Broker | Kafka 서버 클러스터의 각 노드 | 데이터를 저장하고, Producer와 Consumer 사이의 메시지 교환을 관리하며, 분산 처리를 담당함 |
| Zookeeper | 분산 시스템을 위한 코디네이션 서비스 | Kafka 클러스터의 메타데이터 관리, 브로커와 파티션의 상태 관리, 브로커 간의 동기화 담당 |
| Producer | 데이터를 Kafka 토픽(Topic)으로 전송하는 클라이언트 | 웹 애플리케이션, IoT 기기 등에서 생성된 데이터를 Kafka 주제로 전송 |
| Consumer | Kafka 토픽(Topic)로부터 데이터를 읽어오는 클라이언트 | 주제에서 데이터를 읽어와서 처리하는 애플리케이션, 예: 실시간 분석, 저장소에 저장 |
Kafka Broker
카프카 클러스터는 하나 이상의 서버 (kafka brokers)로 구성되어 있습니다.
Producer나 Consumer는 별도의 애플리케이션이지만 Broker는 카프카 자체입니다.
Producers는 Broker 안의 Topic에 레코드를 push하는 프로세스 입니다.
Consumer는 record를 Kafka topic에서 가져옵니다.
Topic은 여러 Broker에 걸쳐 존재할 수 있습니다.
하나의 broker로 Kafka를 운영하는 것도 가능하지만 데이터 복제와 같은 카프카 cluster가 주는 이점을 사용하지 못하게 됩니다.
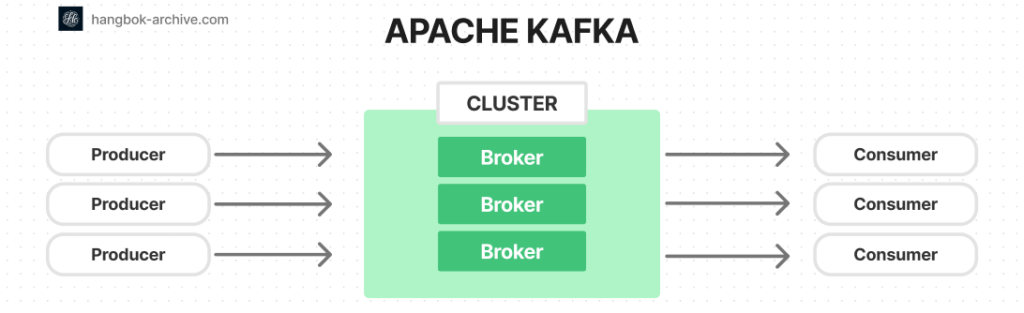
broker들의 관리는 Zookeeper에 의해 수행됩니다.
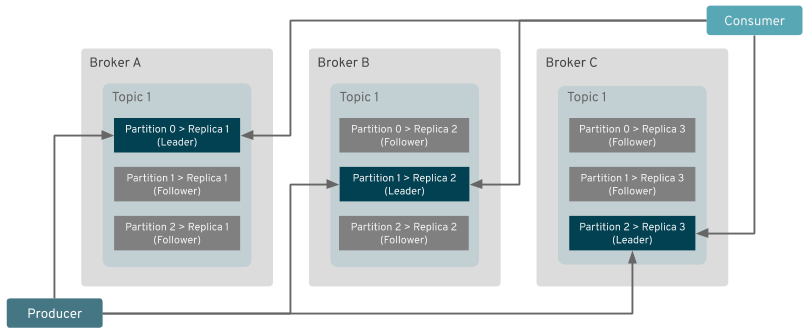
위 그림에서 동일한 Topic이 여러 Broker에 걸쳐 분배되어 있는 것에 주목해주세요.
Producer가 Broker의 partition에 데이터를 넣으면 Broker들 사이에서 데이터를 복제를 합니다.
Consumer는 Leader 파티션에 있는 데이터에만 우선 접근을 합니다. 그러다 시스템 결함이 발생하면 replica 데이터에 접근을 하는 구조 입니다.
Kafka Zookeeper
Zookeeper는 Apache Kafka가 클러스터의 카프카 브로커를 관리하고 조정하는 데 사용하는 분산 조정 서비스입니다.
Zookeeper는 브로커 가용성, 파티션 리더십 및 구성 변경과 같은 브로커 메타데이터를 추적하여 카프카 클러스터를 관리하는 데 도움을 줍니다.
분할 브레인 시나리오를 방지하고 고가용성을 보장하려면 홀수 개의 Zookeeper 노드를 보유하는 것이 좋습니다.
가장 일반적인 설정은 3개 또는 5개의 Zookeeper 노드입니다
NOTE. 분할 브레인 상황 (split-brain situation) 이란?
분할 브레인 상황은 네트워크 파티션이 클러스터를 두 개 이상의 세그먼트로 나누고 각 세그먼트가 전체 클러스터라고 믿는 분산 시스템에서 발생합니다.
각 세그먼트가 다른 세그먼트를 인식하지 못한 채 독립적으로 작동하므로 이로 인해 충돌하는 작업과 데이터 불일치가 발생할 수 있습니다.
예를 들어 5개의 노드(A, B, C, D, E)가 있는 Kafka 클러스터가 있다고 가정해봅니다.
네트워크 문제로 인해 클러스터가 두 개의 세그먼트(A, B)와 (C, D, E)로 분할되는 경우 두 세그먼트 모두 다음을 수행할 수 있습니다.
파티션의 새로운 리더를 선출합니다.
읽기 및 쓰기 요청을 독립적으로 계속 처리합니다.
네트워크 문제가 해결되면 두 세그먼트의 데이터 및 리더십 상태가 서로 다르기 때문에 조정이 필요한 충돌이 발생합니다.
이런 상황을 분할 브레인 상황이라고 하며, 이를 해결하기 위해 과반수 쿼럼을 사용합니다.
다수의 노드를 보유한 세그먼트만 계속해서 결정을 내리고 요청을 처리할 수 있습니다.
이렇게 하면 네트워크 분할 중에 하나의 세그먼트만 활성 상태로 유지됩니다.
Kafka Topic
Topic의 개념
Topic는 레코드가 임시적으로 저장된 논리적 버퍼 입니다.
앞서 말했듯이 모든 카프카 레코드는 Topic으로 구성됩니다.
Producer 애플리케이션은 Topic에 데이터를 쓰고, Consumer 애플리케이션은 Topic에서 읽는거죠
Topic은 논리적으로 하나의 저장공간이지만 물리적으로는 여러 노드(Broker)에 걸쳐 분산될 수 있습니다.
Topic을 여러 물리 노드에 분산하여 실시간 데이터를 로드 벨런싱 할 수 있게 되는거죠.
Topic의 Partition
Topic은 여러 파티션으로 나누어 데이터를 분배할 수 있습니다.
기본적으로 Round Robin 방식으로 데이터를 균일하게 분배합니다.
각 파티션은 지속적으로 추가되는 순서 있고 변경할 수 없는 레코드 시퀀스입니다.
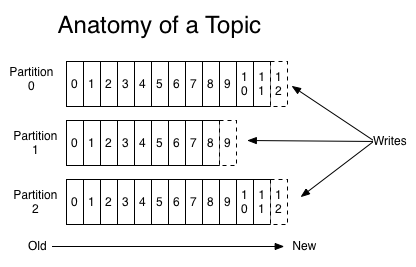
각 파티션에 라운드로빈 방식으로 데이터가 분배 된다면 Partition 0/0 -> Partition 1/0 -> Partition 2/0 -> Partition 0/1 -> Partition 1/1 -> Partition 2/1 -> Partition 0/2 -> … 순서대로 분배가 됩니다.
파티션 내의 각 레코드에는 고유 식별자인 오프셋이 있습니다
Cosumer는 오프셋을 사용하여 파티션에서의 위치를 추적합니다.
오프셋을 통해 소비자는 레코드를 생성된 순서대로 읽고 특정 지점부터 다시 읽을 수 있습니다.
Consumer 장애 발생 후 재가동시에도, 마지막으로 읽었던 위치부터 다시 읽을 수 있게 해주는 이정표 같은 것이죠
Note. Broker(node) 와 Partition 개념
| Aspect | Node (Broker) | Partition |
|---|---|---|
| Definition | Kafka 클러스터의 서버 | Topic의 논리적 구분 |
| Role | 데이터 저장소 관리, 클라이언트 요청 처리, 데이터 복제 | 레코드를 순서대로 저장하고 병렬 처리 가능 |
| Quantity | 여러 브로커가 Kafka 클러스터를 형성합니다 | Topic는 여러 파티션을 가질 수 있습니다 |
| Responsibility | 파티션 처리, 내결함성 보장, Zookeeper | 레코드를 포함하고, 순서를 유지하며, 복제를 지원합니다 |
Topic의 보존
Cluster에 게시된 레코드는 구성 가능한 보존 기간이 지날 때까지 클러스터에 유지됩니다.
보존 정책은 시간(예: 7일 동안 보존) 또는 크기(예: 최대 10GB 보존)를 기준으로 구성할 수 있습니다.
Kafka Producer
실시간 데이터를 카프카 Topic에 전달하는 모듈입니다.
일반적으로 데이터 소스가 같다면, 동일한 토픽으로 데이터를 전달하게 됩니다.
여러 Producer가 하나의 Topic으로 메시지 전달도 가능합니다.
Kafka Consumer
Topic으로 접속하여 데이터를 가져오는 모듈입니다.
Consumer는 어느 파티션에 데이터가 있는지 인지하고 가져옵니다.
여러 Consumer가 하나의 Topic에서 메시지를 전달 받을 수도 있습니다.
여러 Consumer는 하나의 Consumer group으로 묶을 수 있습니다.
Partition은 consumer group 당 단 하나의 consumer의 접근만을 허용합니다.
이러한 규칙을 partition ownership이라고 하는데요.
아래 그림을 보면 cosumer group의 partition ownership 개념을 쉽게 이해할 수 있습니다.
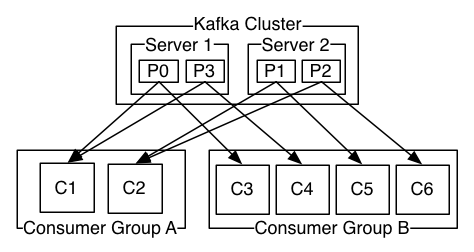
파티션의 레코드는 그룹 내 한 명의 소비자만 소비할 수 있으므로 동일한 그룹 내에서 중복 처리가 발생하지 않게 되는 것을 알 수 있습니다.
반면에 다양한 consumer group이 동일한 데이터를 독립적으로 읽을 수 있으므로 여러 애플리케이션이 동일한 레코드를 다양한 방식으로 처리할 수도 있습니다.
또한 특정 consumer에서 fault가 발생하면, 파티션 재조정(리밸런싱)을 통해 다른 consumer가 해당 파티션을 인수합니다.
offset 정보를 cosumer group 사이에 공유하고 있기 때문에 fault가 발생한 consumer가 중단한 지점부터 계속해서 읽을 수 있는거죠.
이를 통해 데이터 손실이 없도록 하고 지속적인 메시지 처리를 유지할 수 있습니다.
참고하면 좋은 글

참고한 글

Accessing Apache Kafka in Strimzi: Part 1 – Introduction | Red Hat Developer

What’s Split Brain and how to avoid it like the plague? (starwindsoftware.com)

