
“해시 테이블“은 키-값 쌍을 효율적으로 저장하고 검색할 수 있는 강력한 데이터 구조입니다. 체계적이고 매우 빠른 주소록이라고 생각하면 됩니다. 이를 통해 고유 식별자를 기반으로 정보를 빠르게 찾을 수 있습니다.
해싱의 개념
해시 테이블의 핵심은 해싱 개념입니다. 해싱은 저장하려는 각 정보에 대해 고유한 지문을 생성하는 것과 같습니다.
고유 식별자(키)
각 정보에는 키라고 하는 고유 식별자가 있습니다. 예를 들어 주소록에서 이름은 키가 될 수 있습니다.
해시 함수
이 함수는 키를 가져와 고정된 크기의 문자열(주로 해시 코드)로 변환합니다. 이는 이름을 특정 숫자 집합으로 변환하는 것과 같습니다.
이 해시 코드는 해당 키-값 쌍이 저장될 해시 테이블 내의 위치를 결정합니다.
해시 테이블에 해싱은 왜 쓰이고, 키 값으로 해시 코드는 왜 쓰이는가?
해시코드를 도서관의 ID와 비교하면서 설명하는 글들을 많이 봤는데요.
그러면 “해시 코드를 키로 잡지 않고 그냥 원시 키를 사용해서 값 들을 연결하면 되지 않나?”
라는 생각이 들었습니다.
이에 대해 공부하다가 될 만한 내용이 있어서 정리해 보았습니다.
메모리 사용량 감소
해시 코드는 일반적으로 원시 키보다 작기 때문에 해시 테이블을 저장하고 관리할 때 메모리 사용량이 줄어들 수 있습니다. 해시 코드가 작을수록 메모리를 더 효율적으로 사용할 수 있습니다
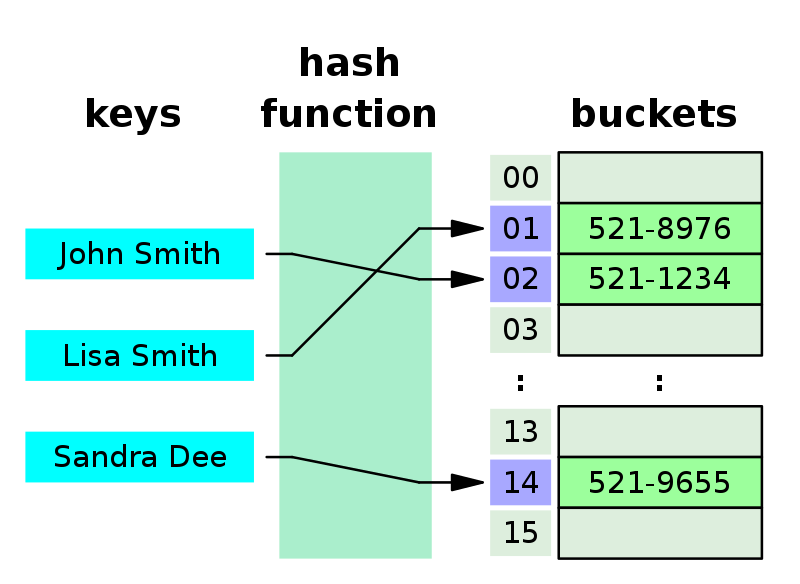
위키피디아의 예제 그림인데요
(Key, Value)가 (“John Smith”, “521-1234”)인 데이터를 크기가 16인 해시 테이블에 저장하는 과정입니다.
- index = hash_function(“John Smith”) % 16 연산을 통해 index 값을 계산한다.
- array[index] = “521-1234” 로 전화번호를 저장하게 된다.
이러한 구조로 데이터를 저장하면 Key값으로 데이터를 찾을 때 해시 함수를 1번만 수행하면 되므로 매우 빠르게 데이터를 저장/삭제/조회할 수 있습니다.
때문에 해시테이블의 평균 시간복잡도가 O(1) 인 것이며 곧 해시 테이블을 사용하는 이유가 됩니다.
해시 충돌 (Hash Collision)
이상적인 시나리오에서는 다른 키를 지정하면 해시 충돌이 없어야 합니다. 잘 설계된 해시 함수는 서로 다른 키가 해시 테이블의 서로 다른 인덱스에 매핑되도록 보장하여 고유한 입력에 대한 고유한 해시 코드를 생성하는 것을 목표로 합니다.
하지만 해시 함수를 사용하여 키를 인덱스에 매핑하는 과정에서 충돌이 발생할 수 있습니다.
정말 극단적인 예를 들어서 해시코드를 만드는 해시 함수가 %7라고 한다면,
50과 85를 키로 입력 되었을 때 동일한 값 1이 해시 테이블의 인덱스로 매핑되기 때문에 충돌이 발생 한다는 겁니다.
위에서는 극단적인 예로 충돌이 발생하는 경우를 만들어 봤는데요
실제 충돌이 발생하는 이유는 다음과 같습니다.
유한 출력 범위
해시 함수는 일반적으로 입력 크기에 관계없이 고정 크기 출력(해시 코드)을 생성합니다.
제한된 범위의 가능한 해시 코드를 사용하면 사용 가능한 해시 코드보다 많은 키가 충돌을 보장하는 비둘기집 원리로 인해 서로 다른 키가 동일한 해시 코드로 끝날 수 있습니다.
무한한 입력 공간
해시 함수는 무한한 공간(가능한 모든 키)에서 입력을 처리하지만 출력 공간은 제한되어 있습니다.
무한한 입력 공간과 유한한 출력 공간 사이의 불일치로 인해 두 개의 서로 다른 키가 동일한 해시 코드를 생성할 가능성이 높아집니다.
불균등한 분포
잘못 설계된 해시 함수는 사용 가능한 해시 코드 전체에 키를 고르지 않게 배포하여 특정 지역에 집중할 수 있습니다. 이러한 고르지 못한 분포로 인해 충돌 위험이 높아집니다.
충돌 해결 (Collision Resolution)
해시 충돌이 발생한 경우, 이를 해결하는 방법이 필요합니다.
일반적인 해결 방법으로는 체이닝(Chaining)과 개방 주소법(Open Addressing) 등이 있습니다.
체이닝(Chaining)
체인닝는 여러 키가 동일한 인덱스 또는 버킷에 해시되는 상황을 관리하기 위해 해시 테이블에 사용되는 충돌 해결 기술입니다.
해당 인덱스에 모든 값을 직접 배치하는 대신 연결 리스트나 다른 데이터 구조를 사용하여 동일한 해시 코드와 관련된 요소 체인을 만듭니다.
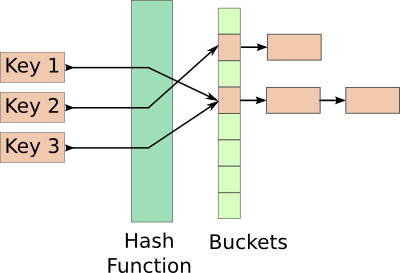
개방 주소법(Open Addressing)
개방 주소법은 충돌한 경우 다른 빈 버킷을 찾아 데이터를 저장하는 방식 입니다.
마치며
해시 테이블 개념을 온라인으로 공부하면서 정리하려니 끝이 없네요… DFS로 가려니 끝이 없습니다…ㅎ
오늘은 우선 여기까지만 정리하고 다음에 추가 정리해보겠습니다.
참고하면 좋은 글

shared memory and can thus easily be used across applications. This is
ideal for simple caches of data that reside in multiple applications. My
specific use case was the Nepomuk Resource class, which is a
glorified cache of key value pairs and uses a hash table. A considerable
amount of effort has gone into making sure that each application’s
Resource classes are consistent with the other applications.