
들어가며
블로그나 간단한 빅데이터분석기사 교재를 보면 홀드 아웃 개념, k-fold cross validation 개념이 너무 간략하게 나와서 명확하게 이해가 되지 않았습니다. 이를 명확하게 이해하기 위해서 해외 블로그를 몇 개 뒤져가며 공부를 하였고, 해당 내용을 정리하였습니다.
이번 포스트에서는 데이터 분할 방법 중 가장 단순한 방법인 “홀드아웃” 에 대해 정리해보았습니다.
홀드아웃 : 데이터 분할을 하는 이유
전체 데이터를 다양한 알고리즘을 사용하여 모델을 훈련하는 데 사용하는 경우 모델을 평가하고 최적화 할 수 없습니다.
모델링에서 가장 중요한 작업은 모든 모델 중에서 일반화 오류가 가장 낮은 모델을 찾는 것입니다.
일반화 오류가 낮은 모델이란 테스트한 데이터 외에 미래의 또는 새로운 데이터 세트에 대해서도 더 나은 예측을 하는 것을 의미합니다.
모델이 하나의 데이터 세트에서 훈련되고 다른 데이터 세트에서 검증 및 테스트되는 메커니즘이 필요한 이유가 바로 일반화 성능 때문입니다.
이를 위해 등장한 것이 홀드아웃 방법입니다.
홀드아웃 : Training + Testing 데이터 세트
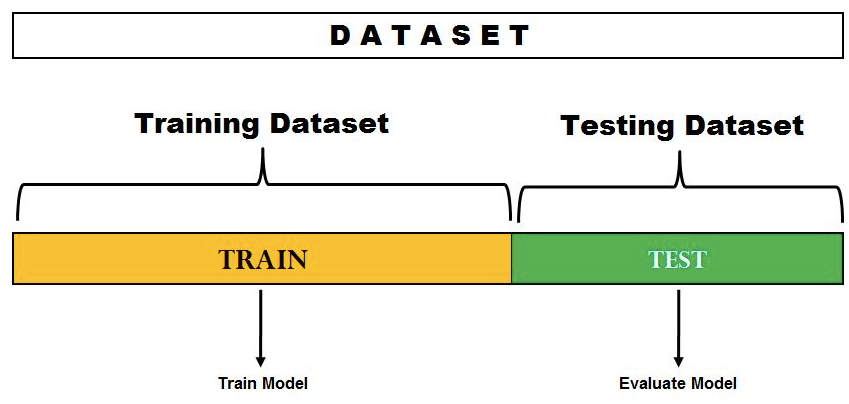
위 다이어그램에서 데이터 세트가 두 부분으로 분할되어 있음을 알 수 있습니다.
하나의 분할은 모델 학습을 위해 따로 사용되고 다른 세트는 모델 테스트 또는 평가를 위해 따로 보관됩니다.
분할 비율은 훈련 목적으로 사용할 수 있는 데이터의 양에 따라 결정됩니다.
일반적으로 70-30% 분할은 데이터 세트를 분할하는 데 사용되며, 데이터 세트의 70%는 훈련에 사용되고 30% 데이터 세트는 모델 테스트에 사용됩니다.
이 프로세스는 데이터세트를 훈련 및 테스트 데이터세트로 분할하고 고정된 하이퍼파라미터 세트를 사용하는 기반의 모델 평가에 사용됩니다.
홀드아웃 : Training + Validation + Testing 데이터 세트
홀드아웃 방법은 모델 선택이나 하이퍼파라미터 튜닝에도 사용할 수 있습니다.
모델 선택을 위한 홀드아웃 방법에서는 데이터세트가 훈련(training), 검증(validation), 테스트(test) 데이터세트라는 세 가지 다른 세트로 분할됩니다.
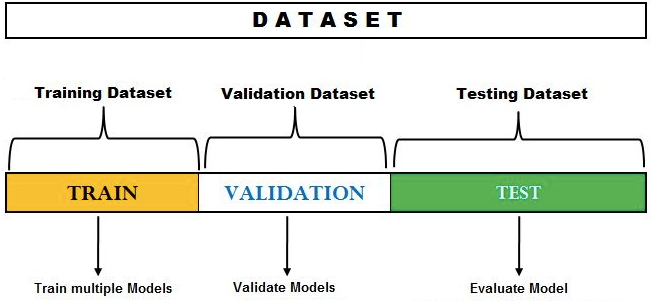
홀드아웃 사용 시 유의사항
데이터를 세 개의 서로 다른 세트로 분할하여 홀드아웃 방법을 사용할 때 훈련, 검증 및 테스트 데이터세트가 전체 데이터세트를 대표하는지 확인하는 것이 중요합니다.
그렇지 않으면 모델이 보지 않은(unseen) 데이터에 대해 제대로 작동하지 않을 수 있습니다.
홀드아웃 프로세스
다음 프로세스는 모델 선택을 위한 홀드아웃 방법을 나타냅니다.
- 데이터 세트를 훈련 데이터 세트, 검증 데이터 세트, 테스트 데이터 세트의 세 부분으로 나눕니다.
- 다양한 기계 학습 알고리즘을 사용하여 다양한 모델을 훈련합니다. 예를 들어 로지스틱 회귀, Random Forest, XGBoost 등을 사용하여 분류 모델을 학습합니다.
- 2단계에서 언급된 각 알고리즘에 대해 하이퍼파라미터 설정합니다.
- 검증 데이터 세트에서 이러한 각 모델의 성능을 테스트합니다.
- 검증 데이터 세트에서 테스트한 모델 중 가장 최적의 모델을 선택합니다. 가장 최적의 모델은 특정 알고리즘에 대해 가장 최적의 하이퍼파라미터 설정을 갖습니다.
- 테스트 데이터 세트에서 가장 최적의 모델 성능을 테스트합니다.
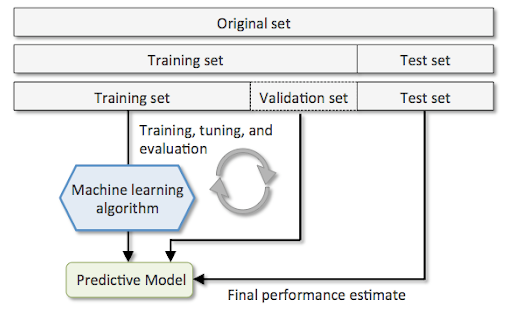
위의 내용은 다음 다이어그램으로 표현 될 수 있습니다.
원본 데이터 세트가 세 가지로 분할되어 있다는 점에 유의하세요.
학습, 튜닝, 평가(validation) 과정을 여러 번 반복하고 가장 최적의 모델을 선택합니다.
최종 모델은 테스트 데이터 세트에서 평가됩니다.
파이썬에서 홀드아웃 데이터 분할
test 데이터를 20% 사용하고, 나머지 80% 데이터 중 75%는 training에 25%는 validation으로 분할하는 방법입니다.
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split the data into training, validation, and test datasets
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=0.25, random_state=42)데이터 분할 후, 모델링하고 검증, 테스트까지 진행한다면 아래와 같이 코드가 작성될 수 있습니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split the data into training, validation, and test datasets
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=0.25, random_state=42)
# Initialize and train the model
model = LogisticRegression()
model.fit(X_train, y_train)
# Make predictions on the validation dataset
y_pred = model.predict(X_val)
# Evaluate the model performance on the validation dataset
accuracy = accuracy_score(y_val, y_pred)
print(f"Validation Accuracy: {accuracy}")
# Make predictions on the test dataset
y_pred_test = model.predict(X_test)
# Evaluate the model performance on the test dataset
accuracy_test = accuracy_score(y_test, y_pred_test)
print(f"Test Accuracy: {accuracy_test}")홀드아웃 방법의 단점
전체 데이터를 훈련하여 모델을 만드는 것보다는 검증 및 테스트 데이터로 나누고 훈련하기 때문에 더 좋은 모델을 만들 수는 있지만 다음과 같은 단점이 존재할 수 있습니다.
홀드아웃 분할법을 사용하면 분할이 무작위가 아닌 경우 결과가 편향될 수 있습니다.
또한 모델이 테스트 데이터 세트에만 잘 들어맞을 수 있는 가능성이 항상 있습니다.
최종 모델은 테스트 데이터와 관련하여 잘 맞도록(또는 과적합) 훈련되었기 때문에 보이지 않거나 미래의 데이터 세트에 대해 일반화 성능이 떨어 질 수 있습니다.
때문에 이런 단점들이 보완된 다른 데이터 분할 법들이 존재합니다. (K-fold CV)
마치며
홀드아웃은 간단한 개념이지만 이것마저도 train_test_split() 함수를 이용하면 간단하게 구현 할 수 있습니다.
이 다음에는 본격적으로 많이 사용되는 데이터 분할방법인 k-fold 교차검증 방법에 대해서 정리해보겠습니다.