2025년 새해가 밝으며 인공지능(AI) 기술은 또 한 번의 격변을 예고했습니다. 기술의 발전 속도에 대한 기대와 동시에, 그 방향성에 대한 막연한 불안감이 교차하는 시점입니다.
특히 지난 1월은 AI 업계의 판도를 뒤흔든 중대한 사건들로 가득했습니다. 중국발 ‘오픈소스’ 공세가 지정학적 긴장을 고조시켰고, 새로운 AI 모델들이 치열한 성능 경쟁을 벌였으며, AI의 활용 방식 또한 질적으로 변화하기 시작했습니다.
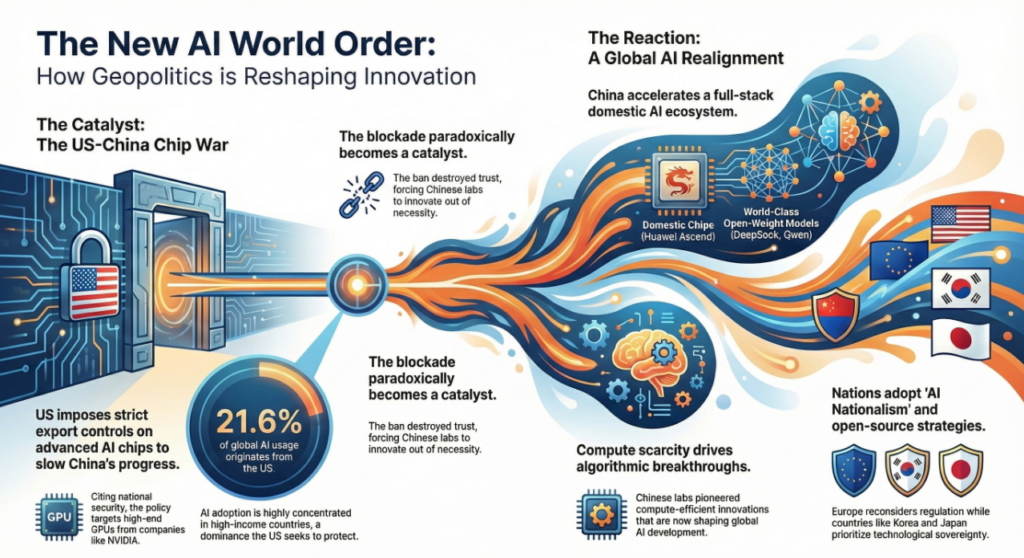
1. 지정학적 지형을 뒤흔든 ‘딥시크 쇼크’
중국의 오픈소스 공세: 딥시크 R1 공개
[1], [2]
2025년 1월, 중국의 AI 스타트업 딥시크(DeepSeek)는 업계에 거대한 충격을 안겼습니다. OpenAI의 주력 모델인 o1과 필적하는 성능을 갖춘 R1 모델을 ‘오픈 웨이트(open-weight)‘ 방식으로 전격 공개했기 때문입니다.
수학, 코딩, 추론 등 다양한 작업에서 높은 성능을 보인 이 모델의 등장은 기술 커뮤니티를 열광시켰고, 동시에 폐쇄형 모델을 고수하던 빅테크와 개방형 생태계 간의 새로운 경쟁 구도를 형성했습니다. 이 사건은 단순히 기술 경쟁을 넘어, AI 패권을 둘러싼 미국과 중국의 대립을 더욱 심화시키는 기폭제가 되었습니다.
오픈 웨이트란?
오픈 웨이트(Open Weight)란, 기업이 자사의 모델에 사용된 **정확한 파라미터와 가중치(weights)**를 공개하는 것을 의미합니다. 일반적으로 MIT 라이선스와 같은 허용적인 라이선스 하에 제공되며, 사용자는 이를 다운로드하여 자신의 인프라 환경에서 모델을 실행하거나 파인튜닝할 수 있습니다.
다만 이는 엄밀한 의미의 오픈 소스(open source)와는 구분됩니다. 모델의 가중치는 공개되더라도, 전체 학습 데이터나 학습 코드까지 함께 공개되는 것은 아닐 수 있기 때문입니다.
2. 빅테크의 견제와 이중 잣대 논란
[1]
딥시크 R1이 공개되자 OpenAI는 즉각 견제에 나섰습니다. OpenAI는 딥시크가 자사의 독점 모델을 무단으로 복제하기 위해 ‘증류(distillation)’라는 기술을 사용했다고 비난했습니다.
하지만 이러한 OpenAI의 주장은 곧바로 ‘이중 잣대’라는 거센 비판에 직면했습니다.
비평가들은 OpenAI 역시 방대한 양의 웹 데이터를 명시적 허가 없이 모델 학습에 사용해왔다는 점을 지적하며, 경쟁자의 기술 활용을 막으려는 시도는 모순이라고 주장했습니다. 이 논란은 AI 모델 학습 데이터의 저작권 문제를 넘어, 진정한 ‘오픈 AI’란 무엇인가에 대한 근본적인 철학적 논쟁에 불을 붙이는 계기가 되었습니다.
3. 주요 국가들의 ‘AI 민족주의’와 엇갈린 대응
[2]
딥시크 쇼크는 각국 정부가 AI 주권 확보를 위해 상반된 전략을 채택하게 만들었습니다.
- 미국: 트럼프 대통령은 취임 직후 5,000억 달러 규모의 ‘스타게이트’ AI 인프라 계획을 발표하며 AI 패권 의지를 분명히 했습니다. 동시에 대중국 AI 기술 수출 통제를 한층 강화하며 자국 기술을 보호하려는 ‘배타적 AI 민족주의’ 경향을 뚜렷이 보였습니다.
- 유럽: 전통적으로 AI 윤리와 규제를 주도해왔으나, 과도한 규제가 자국 AI 산업의 경쟁력 저하로 이어질 수 있다는 우려가 커졌습니다. 특히 프랑스의 마크롱 대통령을 중심으로 AI 법에 유연성을 부여하여 스타트업을 육성하려는 ‘규제 완화’와 ‘개방성’ 추구 움직임이 나타나고 있습니다.
- 한국: 민감 정보 유출에 대한 우려로 정부 주요 부처와 현대차, 한화그룹 등 대기업에서 딥시크 모델의 내부 사용을 금지했습니다. 대신, 자체적인 한국어 AI 플랫폼 개발에 더욱 박차를 가하며 기술 독립성을 강화하는 방향으로 나아가고 있습니다.
- 일본: 딥시크의 영향력 확대를 계기로 기존의 AI 개발 기본 계획을 전면 재정비하기 시작했습니다. AI 산업 육성 정책과 더불어 보안, 윤리 문제를 심도 있게 검토하고, AI 시대에 급증할 전력 수요에 대비한 에너지 정책까지 함께 마련하는 등 종합적인 대응에 착수했습니다.
2. 2025년 1월, 주목해야 할 새로운 AI 모델들
성능과 효율을 모두 잡은 모델들의 등장
[1], [5]
2025년 1월을 전후하여 성능과 효율성 사이의 균형을 맞춘 주목할 만한 AI 모델들이 다수 공개되었습니다.
- DeepSeek R1: OpenAI의 o1 모델과 대등한 수학, 코드, 추론 성능을 갖춘 오픈 웨이트 모델로, 오픈소스 진영에 새로운 활력을 불어넣었습니다.
- OpenAI o3-mini: 과학, 기술, 공학, 수학(STEM) 분야의 작업에 최적화된 비용 효율적인 추론 모델입니다.
- Qwen2.5-Max: 20조 개의 방대한 토큰으로 학습된 Mixture-of-Experts(MoE) 모델로, 뛰어난 추론 능력을 자랑합니다.
- Mistral Small 3: 240억 개의 파라미터를 가진 모델로, 대형 모델과 경쟁할 만한 성능을 유지하면서도 3배 빠른 추론 속도를 제공하여 효율성을 극대화했습니다.
- Microsoft Phi-4: Unsloth가 수정한 버전이 벤치마크에서 미세하게 더 높은 정확도를 기록했으며, 기본적인 프롬프트 엔지니어링만으로 검열을 쉽게 우회할 수 있는 특징을 보였습니다.
치열해지는 AI 모델 성능 경쟁
[5]
AI 모델들의 성능 경쟁은 더욱 정교한 벤치마크의 등장을 이끌었습니다. 2025년 1월 10일, Wolfram Ravenwolf가 발표한 ‘MMLU-Pro’ 컴퓨터 과학 벤치마크 결과는 이러한 경쟁의 단면을 보여줍니다.
이 벤치마크는 기존의 4지선다형 방식에서 벗어나 10개의 선택지 중 하나를 고르도록 설계되어, 모델이 우연히 정답을 맞힐 확률을 대폭 낮추고 복잡한 추론 능력을 보다 정확하게 평가합니다.
해당 벤치마크에서는 claude-3-5-sonnet, gemini-1.5-pro, QwQ-32B-Preview와 같은 모델들이 상위권을 차지하며 치열한 성능 경쟁을 입증했습니다.
AI 연구의 최전선: 새로운 패러다임의 모색
강화학습(RL)과 지도 미세조정(SFT)의 재평가
[1]
모델의 성능을 끌어올리는 후처리 학습 방식에 대한 심도 있는 연구도 활발히 진행되었습니다. 특히 “SFT Memorizes, RL Generalizes(SFT는 암기하고, RL은 일반화한다)”라는 제목의 연구는 큰 주목을 받았습니다.
이 연구는 지도 미세조정(SFT) 방식이 학습 데이터에 포함된 특정 지식을 암기하는 데 치중하는 경향이 있는 반면, 강화학습(RL)은 학습 데이터 분포를 벗어난 새로운 문제에 대해 더 뛰어난 일반화 성능을 보인다는 사실을 실증적으로 보여주었습니다.
이는 향후 AI 모델의 범용성을 높이기 위해 강화학습의 중요성이 더욱 부각될 것임을 시사합니다.
에이전트 기술의 부상
[4]
2025년 1월 22일 자 “Daily Papers”에 등재된 연구 목록은 AI 에이전트 기술에 대한 학계와 산업계의 높은 관심을 명확히 보여줍니다.
Agent-R(반복적 자가 학습을 통한 에이전트 훈련), UI-TARS(GUI 자동 상호작용 에이전트), Mobile-Agent-E(복잡한 작업을 위한 모바일 보조 에이전트)와 같은 논문들이 대표적입니다.
이 연구들은 공통적으로 AI 에이전트가 사람의 개입 없이 스스로 학습하고, 복잡한 소프트웨어를 조작하며, 다양한 작업을 자율적으로 수행하는 능력을 향상시키는 데 초점을 맞추고 있습니다.
진정한 ‘오픈 AI’를 향한 철학적 고찰
[1]
딥시크의 등장으로 촉발된 ‘오픈소스 AI’ 논쟁은 기술 공개의 범위를 넘어 철학적 차원으로 확장되고 있습니다. AI 연구자 Ksenia Se는 소프트웨어의 ‘네 가지 자유’에서 영감을 받아 ‘AI를 위한 여섯 가지 자유’라는 개념을 제안했습니다.
그녀는 진정한 ‘오픈 AI’는 단순히 코드나 가중치를 공개하는 것을 넘어, AI가 어떻게 생성되고, 공유되며, 통제되어야 하는지에 대한 핵심 철학이 필요하다고 주장합니다.
그녀가 제안한 접근의 자유(모두가 AI 모델과 데이터셋에 접근 가능해야 함), 이해의 자유(AI의 의사결정 과정을 투명하게 이해할 수 있어야 함), 잊힐 자유(프라이버시나 윤리적 이유로 정보를 삭제하거나 잊게 할 수 있어야 함), 과적합으로부터의 자유(정적인 세계관에 갇히지 않고 지속적으로 학습해야 함), 과잉으로부터의 자유(과도한 정렬로 인해 유용성을 잃지 않아야 함) 등은 AI 기술이 특정 소수에게 독점되지 않고 투명하게 발전하기 위해 필요한 원칙들을 제시하며 깊은 논의를 촉발시켰습니다.
4. AI 도입의 현주소: 사용 패턴의 변화
교육 및 과학 분야에서의 사용량 급증
[3]
최근 발표된 Anthropic Economic Index에 따르면, 2025년 1월을 포함한 초기 데이터와 8개월 후인 2025년 8월 데이터를 비교했을 때 AI(Claude) 사용 패턴에 의미 있는 변화가 관찰되었습니다.
코딩 관련 작업이 여전히 36%로 가장 큰 비중을 차지했지만, 지식 집약적인 분야의 사용량이 눈에 띄게 증가했습니다.
8개월 동안 교육 관련 작업의 비중은 9.3%에서 12.4%로, 과학 연구 관련 작업은 6.3%에서 7.2%로 상승했습니다.
이는 AI가 단순 반복 작업을 넘어, 지식의 합성, 분석, 교육 등 고차원적인 지적 활동에 점점 더 깊숙이 활용되고 있음을 보여주는 지표입니다.
단순 협업을 넘어 완전한 위임으로
[3]
사용자가 AI와 상호작용하는 방식 역시 질적으로 변화하고 있습니다.
Anthropic의 보고서에 따르면, 2025년 1월이 포함된 초기 데이터와 8개월 후를 비교했을 때 사용자가 AI에게 완전한 작업을 맡기는 ‘지시형(Directive)’ 대화의 비율이 27%에서 39%로 급증했습니다.
이는 사용자들이 AI를 더 이상 단순한 보조 도구가 아닌, 독립적으로 과업을 수행할 수 있는 작업자로 인식하기 시작했음을 의미합니다.
이러한 변화는 DeepSeek R1이나 o3-mini처럼 더 안정적이고 비용 효율적인 고성능 모델들이 등장하며 사용자의 신뢰를 얻은 직접적인 결과로 분석됩니다.
특히 코딩 분야에서 기존 코드의 오류를 수정하는 작업(-2.9%p)은 줄어든 반면, 새로운 프로그램을 생성하는 작업(+4.5%p)이 크게 늘어난 점은 이러한 변화를 뒷받침하는 강력한 증거입니다.
2025년 1월은 AI 산업의 변곡점이 된 한 달이었습니다.
딥시크 R1의 등장은 오픈소스 모델의 잠재력을 증명하며 폐쇄형 모델 진영에 강력한 도전장을 내밀었고, 이는 곧바로 미·중 기술 패권 경쟁과 맞물려 각국의 ‘AI 민족주의’를 심화시켰습니다.
동시에 AI 모델의 성능 경쟁은 더욱 치열해졌으며, 연구계에서는 에이전트 기술과 같은 새로운 패러다임을 모색하는 움직임이 활발해졌습니다.
참고 자료 (References)
[1] #86: Four Freedoms of truly open AI
[2] #88: Can DeepSeek Inspire Global Collaboration?
[3]Anthropic Economic Index report: Uneven geographic and enterprise AI adoption