이번에는 “Spark 특징”에 대해 공부한 내용들을 정리해보았습니다.
Apache Spark는 빅 데이터 처리 및 분석을 위해 설계된 오픈 소스 분산 컴퓨팅 시스템입니다.
Spark는 Disk 기반의 Hadoop IO에서 나오는 속도 문제를 개선하여 탄생 된 프레임워크 입니다.
Apache Spark 특징 요약 😁
속도
Spark는 메모리 내에서 데이터를 처리하므로 Hadoop MapReduce와 같은 기존 디스크 기반 처리 프레임워크보다 훨씬 빠릅니다.
배치 처리와 실시간 데이터 처리를 모두 처리할 수 있습니다.
😀 Hadoop은 디스크에 저장된 파일이 있어야 데이터 처리 할 수 있기에 배치 처리만 가능한 반면에 Spark는 실시간 처리도 지원해 줍니다.
사용 편의성
Spark는 Java, Scala, Python 및 R로 고급 API를 제공하므로 다양한 개발자가 액세스할 수 있습니다.
또한 다양한 작업을 위한 풍부한 내장 라이브러리 세트도 포함되어 있습니다.
범용성
Spark는 다음을 포함하여 다양한 유형의 데이터 처리 워크로드를 지원합니다.
배치 처리: 데이터 변환을 위해 핵심 Spark API를 사용합니다.
대화형 쿼리: 구조화된 데이터를 쿼리하기 위해 Spark SQL을 사용합니다.
스트림 처리: Spark Streaming를 사용하여 Kafka, Flume, Twitter 또는 HDFS와 같은 소스에서 수집된 데이터를 처리할 수 있습니다.
기계 학습: 확장 가능한 기계 학습 알고리즘을 위해 MLlib를 사용합니다.
그래프 처리: 그래프 및 그래프 병렬 계산을 위해 GraphX를 사용합니다.
확장성
Spark는 단일 서버에서 수천 대의 머신으로 확장되도록 설계되었으며 각각 로컬 컴퓨팅 및 스토리지를 제공합니다.
내결함성
Spark는 원래 변환을 사용하여 손실된 데이터를 재구축하는 데 도움이 되는 계보 기반 데이터 복구 메커니즘을 통해 내결함성을 보장합니다.
Apache Spark 주요 특징
Spark 특징 1. 속도
Hadoop은 중간 중간 모든 단계마다 디스크 input/output이 발생합니다. 이에 따라 발생하는 성능 지연 문제점을 Spark는 메모리 기반 처리로 해결하였습니다.

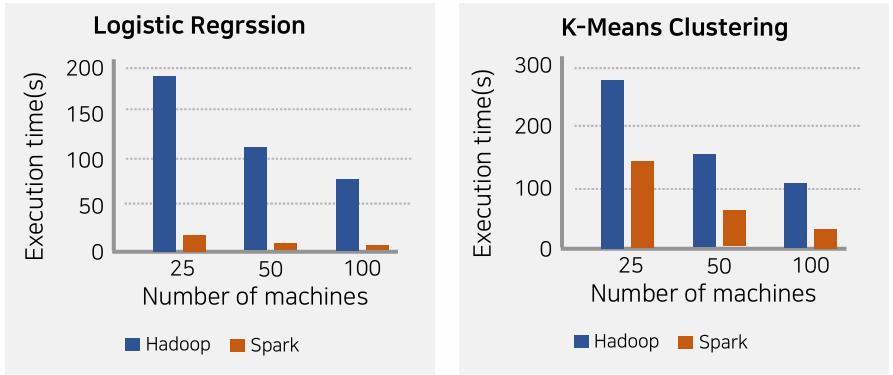
실제 로즈스틱 회귀나 K-measn clustering 작업을 하였을 때 hadoop 보다 spark에서 속도가 획기적으로 개선된 것을 확인 할 수 있습니다.
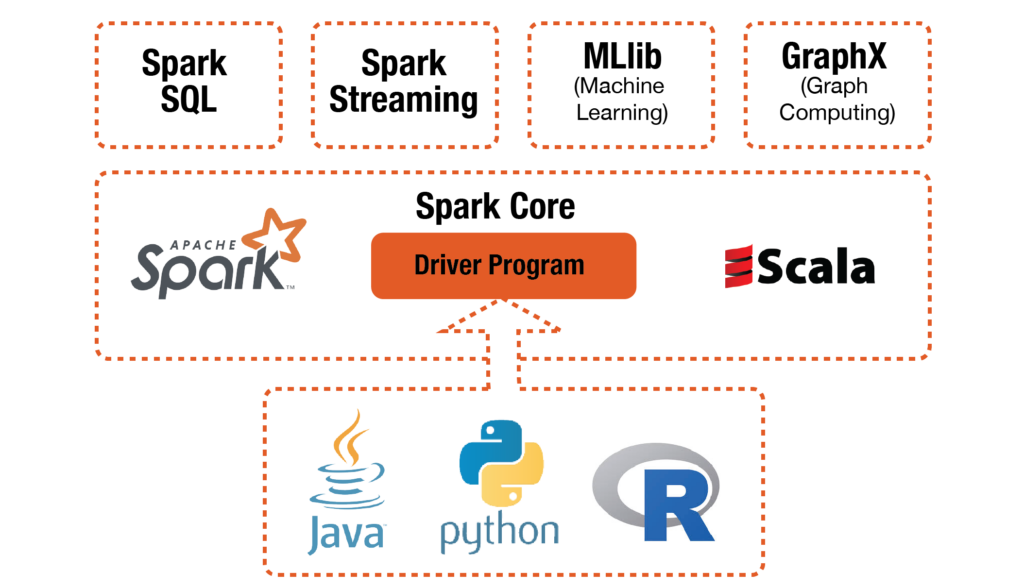
Spark 특징 2. 통합 처리 엔진
Spark는 일괄 처리, 스트림 처리, 대화형 쿼리 등 다양한 유형의 데이터 처리 작업을 위한 통합 엔진을 제공합니다. Hadoop으로만 데이터 처리를 한다면 다른 프레임워크와 같이 사용하였을 때 버전 문제 등 여러 문제가 발생할 수 있습니다.
Spark는 Hadoop과 다르게 이런 문제들을 고민할 필요가 없습니다.
https://moazim1993.github.io/BigData_Spark_Tutorial/

https://moazim1993.github.io/BigData_Spark_Tutorial/

https://moazim1993.github.io/BigData_Spark_Tutorial/
스파크 코어
기본 I/O 기능, 작업 스케줄링, 메모리 관리 및 오류 복구를 담당하는 Spark의 기반입니다. 이는 병렬로 처리할 수 있는 불변의 분산 개체 컬렉션을 나타내는 RDD(Resilient Distributed Dataset)라는 기본 추상화를 제공합니다.
스파크 SQL
SQL 및 DataFrame API를 사용하여 구조화된 데이터로 작업하기 위한 모듈입니다. 다양한 형식(예: JSON, Parquet, ORC)으로 저장된 데이터를 쿼리할 수 있으며 다양한 데이터 소스(예: Hive, JDBC)와 통합됩니다. DataFrame은 RDD보다 높은 수준의 추상화를 제공하고 Catalyst 쿼리 최적화 및 Tungsten 실행 엔진과 같은 최적화를 제공합니다.
스파크 스트리밍
데이터 스트림을 작은 배치(마이크로 배치)로 나누고 Spark의 배치 처리 기능을 사용하여 처리함으로써 실시간 데이터 처리가 가능합니다. Kafka, Flume 및 HDFS를 포함한 다양한 데이터 소스를 지원하고 풍부한 변환 및 출력 작업 세트를 제공합니다.
MLlib
분류, 회귀, 클러스터링, 협업 필터링 등을 위한 알고리즘을 제공하는 확장 가능한 기계 학습 라이브러리입니다. Spark의 인메모리 처리 기능을 활용하여 대규모 기계 학습 작업을 효율적으로 처리합니다.
그래프X
그래프 처리 및 그래프 병렬 계산을 위한 라이브러리입니다. 이는 그래프 생성 및 조작을 위한 API뿐만 아니라 PageRank, 연결된 구성 요소 및 최단 경로와 같은 작업을 위한 내장 그래프 알고리즘 세트를 제공합니다.
Spark 특징 3. 내결함성
메모리 기반의 데이터 처리를 수행하더라도 결함 발생 시 데이터가 복구 가능하도록 설계되었습니다.
데이터의 변경 이력이 추적 되도록 설계함으로써, 처리 데이터의 복구가 가능합니다.
그래프 구조로 변경 이력을 저장하는데요 git의 commit 내역이 남는 것과 유사하다고 생각하면 될 것 같습니다.
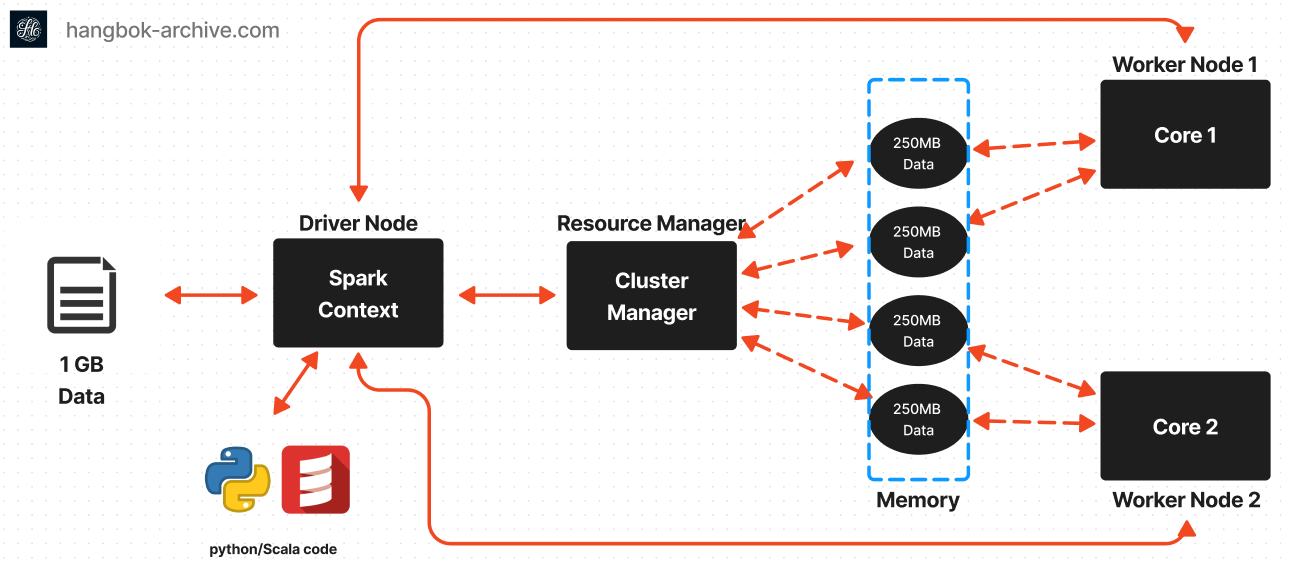
Master/Worker 구조의 분산 시스템 😗
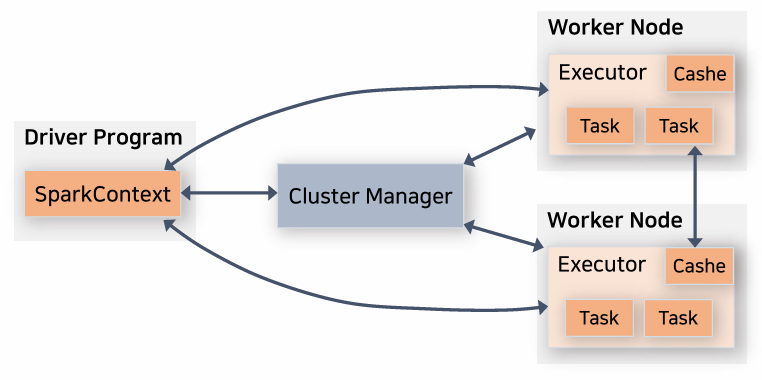
Driver
스파크에서 수행할 전체 작업을 job이라고 부릅니다.
Driver 는 Spark 애플리케이션의 마스터 노드입니다.
모든 task을 조정하고 실행 흐름을 제어합니다
애플리케이션의 main() 함수를 실행하고 Spark 클러스터의 진입점인 SparkContext를 생성합니다.
Cluster Manager
Driver에서 job이 task로 잘 쪼개어 졌다면 이 task를 수행하는 데 필요한 cpu, memory와 같은 리소스들이 있을 것 입니다.
Cluster Manager는 이러한 리소스 요청을 관리합니다.
리소스 관리 manager는 다음과 같은 3가지가 있습니다.
Yarn
강력한 통합 및 리소스 관리 기능이 필요한 Hadoop 중심 환경에 가장 적합합니다.
Mesos
효율적인 리소스 공유가 필요한 다양한 워크로드와 여러 분산 애플리케이션이 있는 환경에 적합합니다.
StardardAlone
사용이 쉽고 설치 요구 사항이 최소화되어 소규모 또는 단순한 설정, 개발 및 테스트 환경에 적합합니다.
Executor
Executor는 Spark 클러스터의 worker 노드입니다.
Driver가 할당한 작업에 대한 실제 계산을 수행하고 Spark 애플리케이션에 대한 데이터를 저장합니다.
코드를 실행하고 상태와 결과를 Driver에 다시 보고합니다.
Spark의 수행 과정 🤔
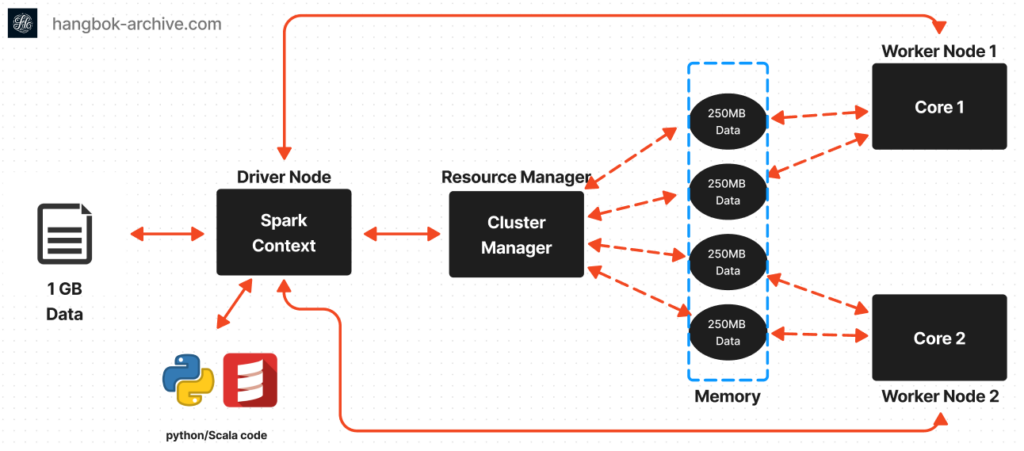
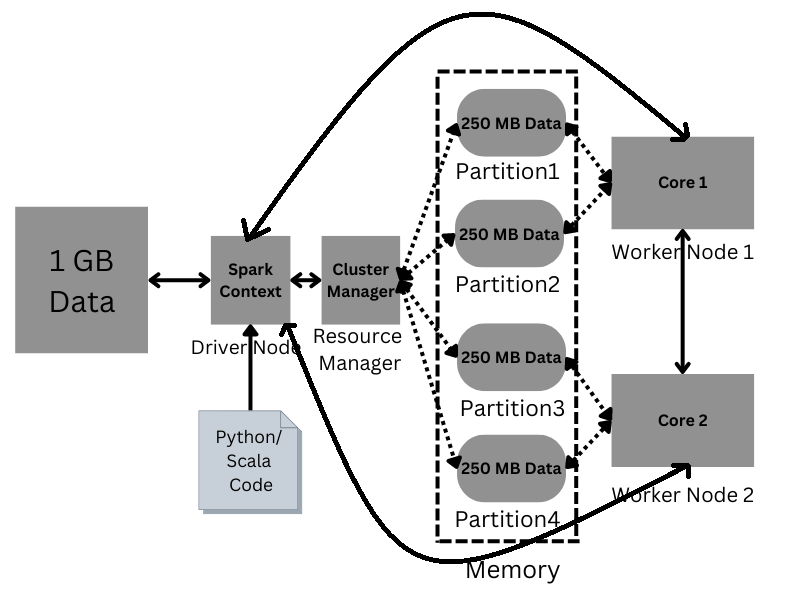
Application Submission: 사용자는 드라이버 프로그램이 포함된 Spark 애플리케이션을 클러스터 관리자(예: YARN, Mesos 또는 Standalone)에 제출합니다.
SparkContext Initialization: 드라이버 프로그램은 Spark 클러스터와 상호 작용하기 위한 진입점인 ‘SparkContext’를 초기화합니다.
Resource Allocation: Cluster manager는 애플리케이션 요구 사항에 따라 클러스터 노드 전체에 리소스(executors)를 할당합니다.
Executor Launching: 할당된 worker 노드에서 executor가 시작됩니다. 이러한 executor는 작업을 실행하고 드라이버에 다시 보고하는 역할을 담당합니다.
Task Scheduling: 드라이버 프로그램은 사용자 정의 변환 및 작업을 directed acyclic graph(DAG)로 변환한 다음 executor에서 이러한 작업을 예약합니다.
Task Execution: executor는 할당된 작업을 실행하여 데이터에 대한 작업을 수행하고 필요에 따라 중간 결과를 메모리나 디스크에 저장합니다.
Data Shuffling: 필요한 경우 ‘reduceByKey’ 또는 ‘join’과 같은 특정 작업을 실행하는 동안 데이터가 셔플됩니다(노드 간 교환).
Result Collection: Task가 완료되면 executor는 결과를 Driver 프로그램으로 다시 보냅니다.
Action Completion: Driver는 결과를 집계하고 필요한 경우 추가 작업을 실행한 후 애플리케이션을 완료합니다.
Resource Cleanup: 애플리케이션이 완료된 후 SparkContext가 중지되고 리소스가 클러스터 관리자에게 다시 해제되며 실행 프로그램이 종료됩니다.
참고한 글
https://medium.com/@k12shreyam/spark-for-parallel-processing-ef234b8ca034