Spark 이해하기 4. Spark Action

Apache Spark Action 은 RDD(Resilient Distributed Dataset)의 변환에 의해 정의된 전체 계산 계획의 실행을 트리거하는 작업입니다. action은 Spark에 계산을 수행하고 결과를 생성하도록 지시하여 Spark가 클러스터 노드에서 실행될 작업을 시작하도록 합니다. action의 예로는 RDD의 모든 데이터를 드라이버 프로그램으로 검색하는 ‘collect()’, RDD의 요소 수를 계산하는 ‘count()’ 등이 있습니다. Spark Action 함수 정리 Action Function Purpose Example Input […]
Spark 이해하기 3. Spark transformation

Spark Transformation 은 작업을 즉시 실행하지 않고 원본 RDD의 각 요소에 함수를 적용하여 새 RDD를 생성하는 RDD(Resilient Distributed Datasets)에 대한 작업입니다.
Spark 이해하기 2. Spark RDD
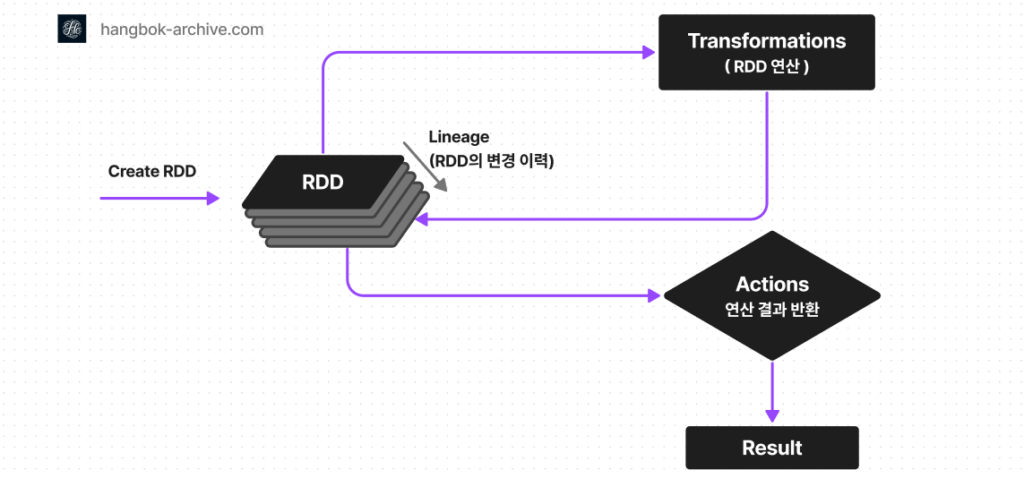
Spark RDD 는 Resilient Distributed Dataset의 약자로써 “복원력 있는 분산 데이터세트”를 나타냅니다. Spark RDD 는 빅데이터 처리를 단순화하고 속도를 높이도록 설계된 Apache Spark의 핵심 데이터 모델입니다.
Spark 이해하기 1. Spark 특징 / 구조
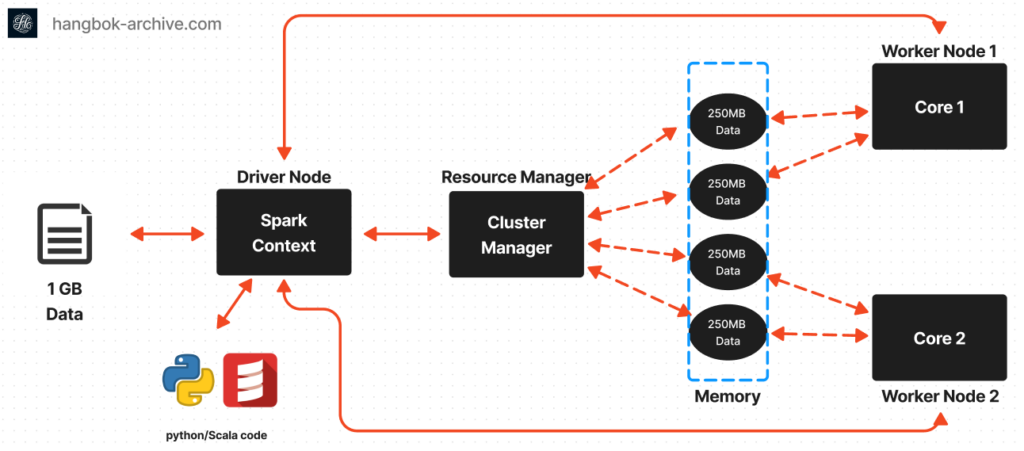
Apache Spark는 빅 데이터 처리 및 분석을 위해 설계된 오픈 소스 분산 컴퓨팅 시스템입니다. Spark는 Disk 기반의 Hadoop 처리 방식을 개선하여 처리속도를 높인 프레임워크인데요.
MSA 이해하기 1. MSA 개념, 장단점

MSA 개념 : 마이크로서비스 아키텍처(MSA)는 애플리케이션이 작고, 느슨하게 결합되고, 독립적으로 배포 가능한 서비스 모음으로 구성된 소프트웨어 개발에 대한 접근 방식입니다.
Hadoop MapReduce 이해하기 (실습 포함)

Hadoop MapReduce는 분산 데이터 처리를 위한 프로그래밍 모델이자 처리 기술입니다. key, value 형태의 자료구조를 기반으로 데이터를 처리하는 메커니즘를 가지는데요. MapReduce의 대략적인 모습은…
Hadoop 개요. HDFS + MapReduce

“Hadoop”은 분산 파일 (HDFS) + 분산 처리 프로그래밍 모델 (MapReduce)을 제공해줍니다. 데이터를 미리 HDFS 형태로 분산해서 저장시킨 다음 MapReduce를 이용해서 분산처리하는 것이죠
Hadoop의 HDFS 시작하기

“HDFS 시작하기” 입니다. 도커 컨테이너를 이용하여 단일 시스템이지만 분산 시스템이라고 가정하고 HDFS 명령어들을 테스트 할 수 있었습니다.해당 포스트는 KMOOC 빅데이터 프레임워크 강의 내용을 기반으로 정리한 글 입니다.
하둡 분산 파일 시스템 HDFS 이해하기

HDFS (Hadoop 분산 파일 시스템)는 Apache Hadoop 에코시스템의 초석으로, 컴퓨터 클러스터 전체에서 방대한 양의 데이터를 저장하고 관리하도록 설계되었습니다. HDFS의 아키텍처는 안정성, 확장성 및 효율적인 데이터 처리를 보장하므로 빅 데이터 애플리케이션에 널리 사용됩니다.
DFS 분산 파일 시스템 개념
분산 파일 시스템 (DFS)은 네트워크 내의 여러 컴퓨터(노드)에 걸쳐 파일을 관리하고 구성하는 파일 시스템 유형입니다. 이는 스토리지에 대한 통합 보기를 제공하므로 데이터가 여러 시스템에 물리적으로 분산되어 있더라도