AI 모델 성능 비교 사이트 :
프로바이더가 자사 모델 카드에 게재하는 점수는 유리한 조건에서 측정되거나 선택적으로 공개될 수 있습니다.
이를 보완하기 위해 제3자 독립 기관 및 커뮤니티가 자체 기준으로 동일한 조건에서 모델들을 평가하고 그 결과를 공개하는 플랫폼들이 존재합니다.
자세한 지표 설명은 아래 포스트를 참고하세요
LM Arena (Chatbot Arena / LMSYS Arena)
사이트: lmarena.ai | 운영: UC Berkeley SkyLab · UC San Diego · Carnegie Mellon University
UC Berkeley SkyLab을 중심으로 한 학술 기관들이 공동 운영하는 크라우드소싱 기반의 인간 선호도 평가 플랫폼입니다.
2023년 5월 출범 이후 현재까지 600만 건 이상의 인간 투표 데이터를 누적하여 업계에서 가장 신뢰받는 실사용 선호도 지표로 자리매김했습니다.
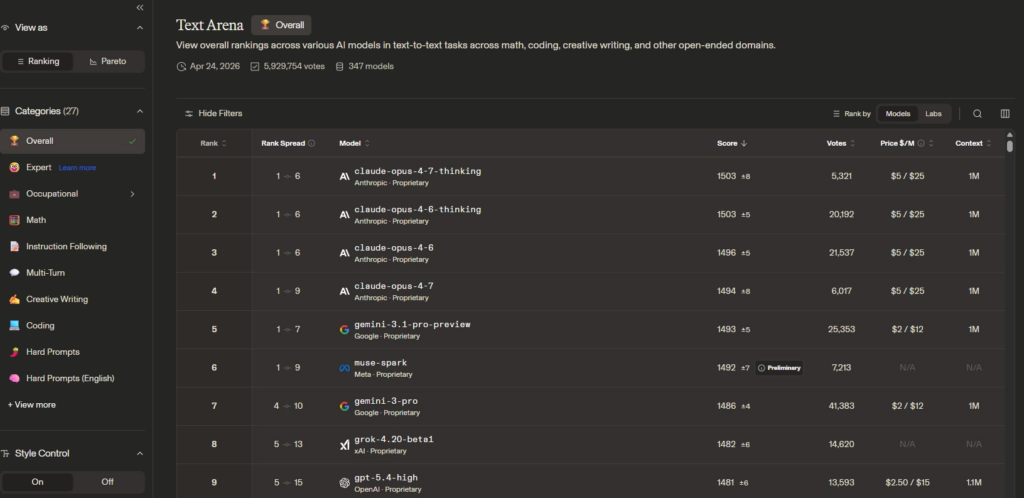
- 평가 방식: 이중 맹검(Double-Blind) A/B 비교 투표. 사용자가 질문을 입력하면 두 익명 모델의 응답이 나란히 제시되고, 사용자가 선호하는 쪽을 투표.
- 점수 방식: Bradley-Terry 모델 기반 Elo 레이팅. 체스의 Elo 시스템과 동일한 원리로, 각 대결 결과에 따라 점수가 실시간 업데이트.
- 카테고리: 종합(General), 코딩, 수학, 창작, 비전(Vision), 웹 개발 등 도메인별 세분화 리더보드 운영.
- 개방성: FastChat 오픈소스로 인프라 공개, 대화 데이터셋도 연구 목적으로 배포.
- 한계: 투표자 집단 편향, 특정 응답 스타일(장황한 답변) 선호 가능성.
Artificial Analysis
사이트: artificialanalysis.ai | 운영: 독립 상업 기관 (2024년 1월 창립, Sydney)
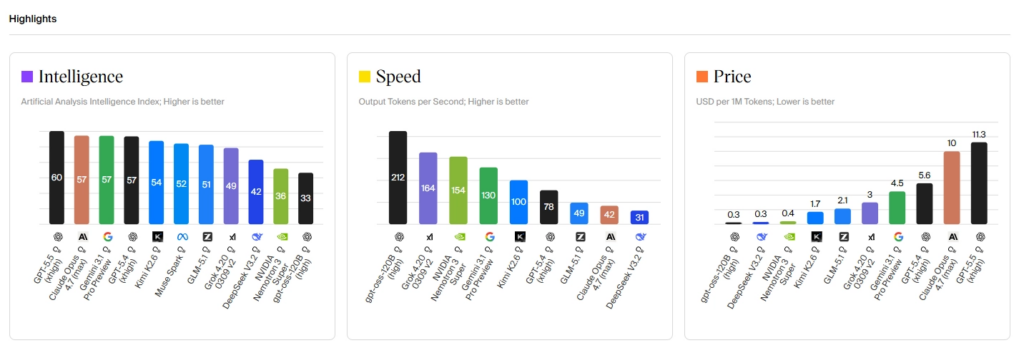
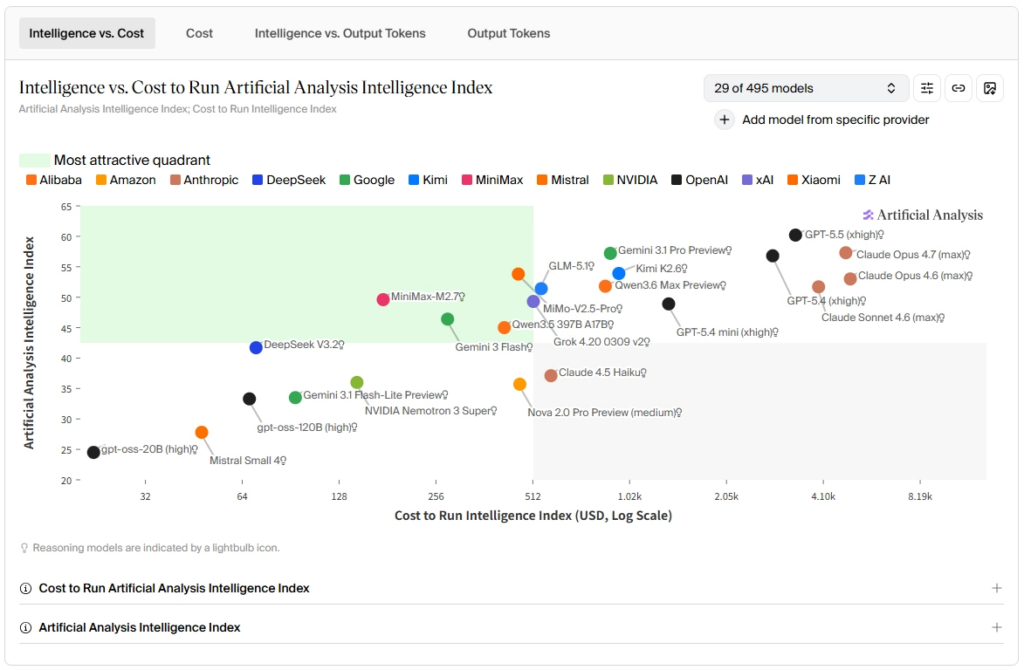
현재 가장 광범위하고 엄밀한 독립 평가를 수행하는 상업 기관으로, AI 엔지니어링 커뮤니티에서 “독립 벤치마킹의 사실상 표준”으로 평가 받습니다.
모든 평가를 자체적으로 직접 실행하며(자체 보고 점수 의존 최소화), “미스터리 쇼퍼(Mystery Shopper)” 정책을 통해 AI 랩들이 자체 도메인을 등록하지 않고 평가를 진행하여 랩들이 Artificial Analysis 전용으로 다른 모델 버전을 서빙하는 것을 방지합니다.
- Intelligence Index V3: MMLU-Pro, GPQA Diamond, HLE, AIME, LiveCodeBench, IFEval, AA-LCR, SciCode, Terminal-Bench Hard, τ²-Bench Telecom 등 10개 벤치마크를 종합한 단일 지수. 모든 런에 대해 95% 신뢰구간 산출.
- 성능 지표: 출력 속도(토큰/초), 첫 번째 토큰까지의 지연(TTFT), 컨텍스트 윈도우, 가격을 추가 측정.
- 업데이트 주기: 하루 8회 개별 요청, 2회 병렬 요청 측정. 72시간 롤링 평균.
- 규모: 328개 모델 랭킹(2026년 4월 기준).
- 비즈니스 모델: 공개 리더보드는 무료, 엔터프라이즈용 인사이트 구독 및 비공개 커스텀 벤치마킹으로 수익화. 공개 리더보드 순위에 비용 지불 불가.
Hugging Face Open LLM Leaderboard
사이트: huggingface.co/spaces/open-llm-leaderboard | 운영: Hugging Face (커뮤니티 주도)
오픈소스 LLM 커뮤니티의 심장부 역할을 하는 플랫폼으로, 오픈 웨이트 모델들을 동일한 하드웨어 환경에서 자동화 평가합니다.
모델 제출이 상시 열려 있어 랭킹이 수시로 갱신되며, 오픈소스 모델 간 공정한 비교의 기준점을 제공합니다.
- 평가 대상: 오픈 웨이트(Open-Weights) 모델에 특화. 독점 모델은 포함하지 않음.
- 평가 방식: EleutherAI의 Language Model Evaluation Harness(lm-eval) 프레임워크 사용. 동일 하드웨어에서 동일 조건으로 자동화 실행.
- 특징: 커뮤니티 누구나 모델 제출 가능. 오픈소스 모델의 프로바이더 주장 점수 검증에 활용.
Stanford HELM (Holistic Evaluation of Language Models)
사이트: crfm.stanford.edu/helm | 운영: Stanford CRFM (Center for Research on Foundation Models)
Stanford CRFM이 2022년 발표한 다차원 종합 평가 프레임워크로, 단순 정확도를 넘어 모델의 전체적인 ‘건강 상태’를 진단하는 것을 목표로 합니다.
단순 벤치마크 점수를 넘어 AI의 사회적 영향과 리스크까지 함께 평가한다는 철학을 지닙니다.
- 7가지 평가 차원: 정확도(Accuracy), 캘리브레이션(Calibration), 강건성(Robustness), 공정성(Fairness), 편향(Bias), 독성(Toxicity), 효율성(Efficiency).
- 평가 범위: 42개 이상의 시나리오, 질의응답·요약·코드 생성·다이얼로그 등 다양한 태스크 포함.
- 투명성: 모든 원시 프롬프트 및 모델 응답을 공개. 오픈소스 Python 프레임워크 제공(GitHub).
- 적합 용도: 규제 준수, 책임 있는 AI 배포, 안전성 중심 모델 선택.
BenchLM.ai
사이트: benchlm.ai | 운영: 독립 커뮤니티 플랫폼
195개 모델, 152개 벤치마크를 집계하는 종합 리더보드 플랫폼입니다.
OpenBench, 공식 모델 논문, 공개 리더보드에서 데이터를 수집하여 표준화된 가중 평균 점수로 통합합니다.
점수의 신뢰도를 나타내는 ‘신뢰 지표(Confidence Indicator, 1~4점)’를 함께 표시하여 근거가 부족한 점수를 구분할 수 있습니다.
| 플랫폼 | 운영 주체 | 평가 방식 | 강점 | 한계 |
|---|---|---|---|---|
| LM Arena | UC Berkeley 등 학술 기관 | 인간 A/B 투표 + Bradley-Terry Elo | 실제 사용자 선호도, 게임화 저항성 | 투표자 편향, 특정 스타일 선호 |
| Artificial Analysis | 독립 상업 기관 | 자체 독립 실행 + 종합 지수 | 가장 엄밀한 독립 측정, 속도·가격 포함 | 유료 심화 데이터 |
| HF Open LLM Leaderboard | Hugging Face 커뮤니티 | 자동화 eval harness | 오픈소스 모델 공정 비교, 실시간 갱신 | 독점 모델 제외 |
| Stanford HELM | Stanford CRFM | 다차원 종합 평가 | 안전성·공정성·편향까지 측정 | 업데이트 주기 느림 |
| BenchLM.ai | 독립 커뮤니티 | 멀티소스 집계 + 신뢰도 지표 | 가장 많은 모델·벤치마크 커버리지 | 일부 점수는 추정치 |
주요 프런티어 모델별 벤치마크 점수 비교 (2026년 4월 기준)
아래 표는 Artificial Analysis, LM Arena, SWE-bench 공식 리더보드 등 독립 평가 기관의 데이터를 기반으로 작성했습니다.
| 모델 | AA 종합 지수 | Arena Elo | GPQA Diamond | AIME 2025 | SWE-bench Verified | LiveCodeBench | HLE |
|---|---|---|---|---|---|---|---|
| Claude Opus 4.7 | 57 | 1504 | 91.3% | – | 82.0% | – | – |
| Gemini 3.1 Pro Preview | 57 | – | 94.3% | – | 80.6% | 91.7% | – |
| GPT-5.4 | 57 | – | 81.0% | 94% | ~80% | – | 53.1% |
| Kimi K2.6 | 54 | – | – | – | – | 89.6% | – |
| Claude Opus 4.6 | 53 | 1500 | – | – | – | – | – |
| DeepSeek V3.2 | – | ~1420 | – | – | – | 89.6% | – |
| Qwen3.5-plus | – | – | 88.4% | 91.3% | 76~78% | – | – |
| GLM-4.7 | – | ~1445 | 85.7% | 95.7% | 73.8% | 84.9% | – |